Introdução Link para o cabeçalho
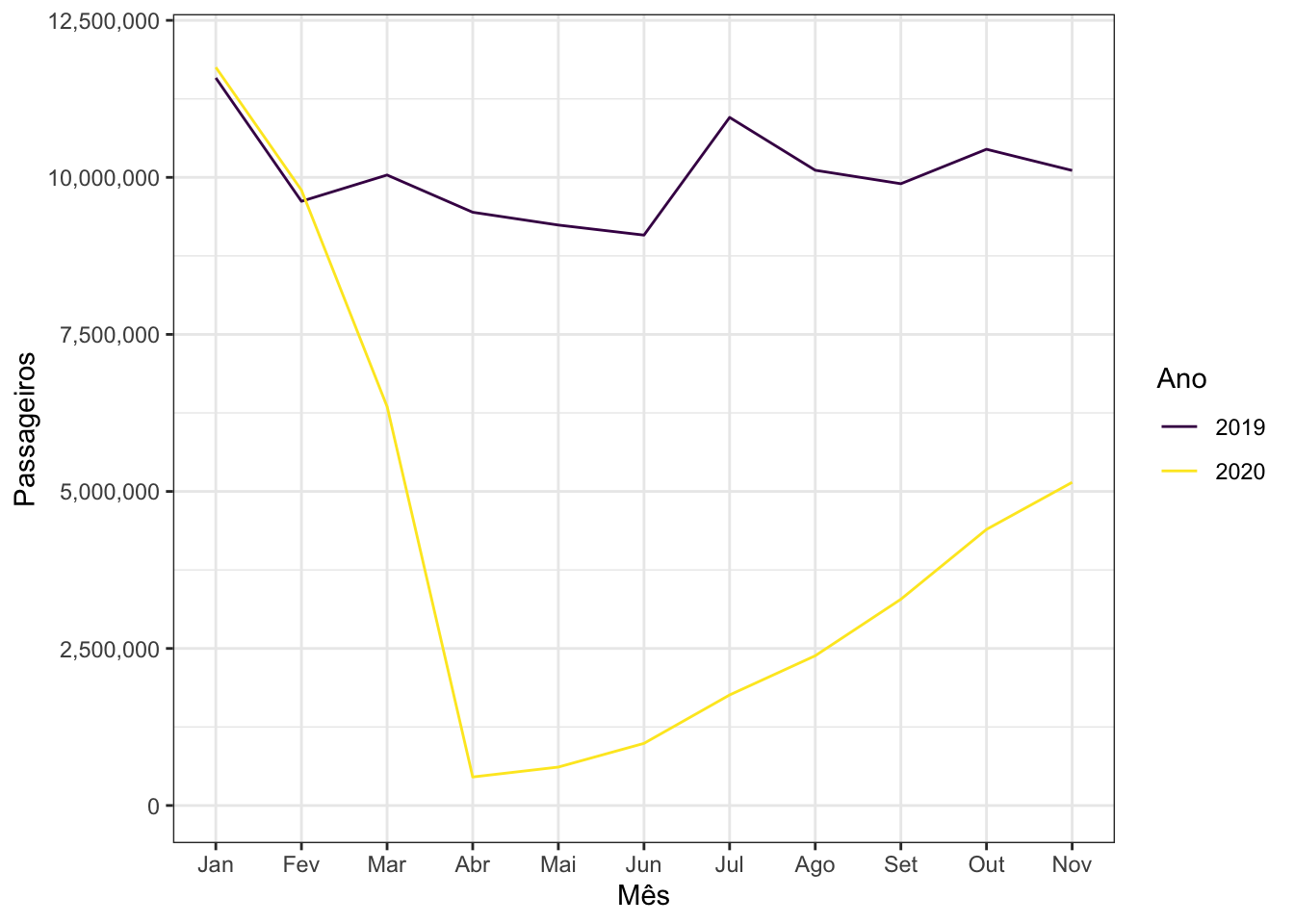
A fim de verificar o impacto da atual pandemia de COVID-19 na aviação brasileira, baixei alguns dos Dados Estatísticos da ANAC para comparar o fluxo de passageiros aéreos entre 2019 e 2020.
Obtenção dos Dados Link para o cabeçalho
Embora eu utilize apenas dois anos na análise, criei um código capaz de baixar informações de todos os anos disponíveis no site da ANAC. Basta editar os valores do objeto anos para fazer isso.
base <- "https://www.anac.gov.br/assuntos/dados-e-estatisticas/dados-estatisticos/arquivos/resumo_anual_"
anos <- 2019:2020
for (j in anos){
download.file(url = paste0(base, j, ".csv"),
destfile = paste0("dados/resumo_anual_", j, ".csv"))
}
Preparação dos Dados Link para o cabeçalho
Após os dados baixados, eles devem ser lidos dentro do R. Como há algumas operações a serem feitas em cada conjunto de dados, eu criei a função preparacao para simplificar esse processo. Essa função lê os arquivos csv e ajusta o nome das suas colunas.
# preparacao dos dados
library(tidyverse)
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.0 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(janitor)
##
## Attaching package: 'janitor'
##
## The following objects are masked from 'package:stats':
##
## chisq.test, fisher.test
preparacao <- function(arquivo){
# leitura
dados <- read.csv(file = arquivo,
sep = ";",
fileEncoding="latin1",
dec = ",")
# nomes das colunas
dados <- clean_names(dados)
return(dados)
}
resumo_anual_2019 <- preparacao("data/resumo_anual_2019.csv")
# retirar dezembro
resumo_anual_2019 <-
resumo_anual_2019 %>%
filter(mes != 12)
resumo_anual_2020 <- preparacao("data/resumo_anual_2020.csv")
dados <-
rbind(resumo_anual_2019, resumo_anual_2020) %>%
mutate(passageiros = passageiros_pagos + passageiros_gratis) %>%
mutate(ano = as.factor(ano)) %>%
select(ano, mes, passageiros) %>%
group_by(ano, mes) %>%
summarise(passageiros = sum(passageiros, na.rm = TRUE))
## `summarise()` has grouped output by 'ano'. You can override using the `.groups`
## argument.
Visualização Link para o cabeçalho
Com os dados lidos e preparados, é trivial fazer a visualização.
ggplot(dados, aes(x = mes, y = passageiros, colour = ano)) +
geom_line() +
labs(x = "Mês", y = "Passageiros", colour = "Ano") +
scale_x_continuous(breaks = 1:12,
labels = c("Jan", "Fev", "Mar", "Abr", "Mai", "Jun",
"Jul", "Ago", "Set", "Out", "Nov", "Dez"),
minor_breaks = NULL) +
scale_y_continuous(limits = c(0, 1.2e7),
labels = scales::comma_format()) +
theme_bw() +
scale_colour_viridis_d()
Os códigos usados nesse post podem ser encontrados no github (me segue lá).