Introdução Link para o cabeçalho
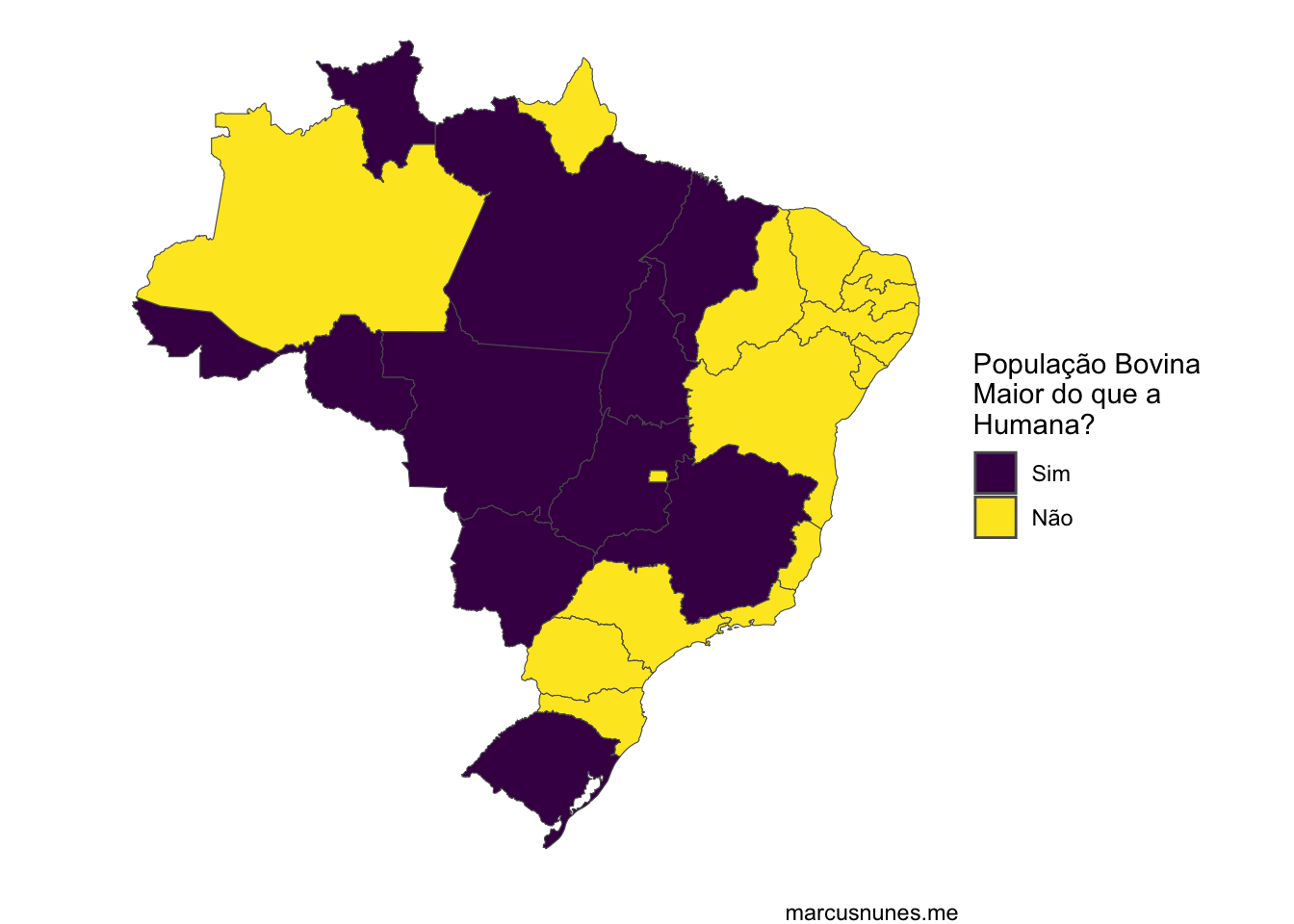
Recentemente um tweet meu hitou, como os jovens dizem. Ao criar um mapa comparando o número de cabeças de gado com a população de cada estado brasileiro
Como mais de 300.000 impressões de um tweet é algo impressionante para o meu perfil, resolvi compartilhar aqui no blog o código usado para este mapa.
Obtenção dos Dados Link para o cabeçalho
Os dados foram baixados do SIDRA: Sistema IBGE de Recuperação Automática. Embora seja possível recuperar estes dados manualmente, eu preferi utilizar o pacote sidrar para baixá-los de maneira automática.
# baixando os dados do sidra do ibge
library(sidrar)
library(tidyverse)
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.0 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
theme_set(theme_bw())
library(janitor)
##
## Attaching package: 'janitor'
##
## The following objects are masked from 'package:stats':
##
## chisq.test, fisher.test
rebanhos <-
get_sidra(x = "3939",
period = "2019",
geo = "State") %>%
clean_names() %>%
filter(tipo_de_rebanho == "Bovino") %>%
select(bovinos = valor, unidade_da_federacao)
## Considering all categories once 'classific' was set to 'all' (default)
populacao <-
get_sidra(x = "6579",
period = "2019",
geo = "State") %>%
clean_names() %>%
select(populacao = valor, unidade_da_federacao)
## Considering all categories once 'classific' was set to 'all' (default)
Veja como é fácil obter as tabelas que nos interessam. Basta informar seu número e a função get_sidra as baixa automaticamente. Uma pequena limpeza é necessária para que os dados fiquem prontos para a análise que desejamos realizar.
Em seguida, é necessário juntar os dados do rebanho bovino e da população. Isso é feito para criar uma variável indicadora, que serve justamente para identificar quais estados possuem mais cabeças de gado do que habitantes.
# juntando os conjuntos de dados de populacao e rebanho
dados <-
left_join(rebanhos, populacao, by = "unidade_da_federacao") %>%
mutate(nome = str_to_upper(unidade_da_federacao)) %>%
mutate(indicador = ifelse(bovinos > populacao, "Sim", "Não")) %>%
mutate(indicador = factor(indicador, levels = c("Sim", "Não"))) %>%
select(-unidade_da_federacao)
Por fim, basta plotar estas informações no mapa do Brasil. Para isso, usei a mesma técnica que já havia utilizado nos posts Análise Descritiva do Coronavírus nos Estados Brasileiros e Visualização do Mapa do Brasil Dividido por Estratos Populacionais aqui mesmo neste blog.
# mapa
library(brazilmaps)
library(sf)
## Linking to GEOS 3.11.0, GDAL 3.5.3, PROJ 9.1.0; sf_use_s2() is TRUE
mapa_br <- get_brmap("State")
mapa_br %>%
left_join(dados, by = "nome") %>%
ggplot() +
geom_sf(aes(fill = indicador)) +
scale_fill_viridis_d() +
labs(fill = "População Bovina\nMaior do que a\nHumana?",
caption = "marcusnunes.me") +
theme_void()
## old-style crs object detected; please recreate object with a recent sf::st_crs()