Recentemente encontrei um conjunto de dados chamado Rate Your Music: The Top 5,000 Most Popular Albums e achei que seria interessante analisá-lo. A minha primeira pergunta a ser respondida com ele é em relação a outliers neste conjunto de dados. Será que, entre os gêneros de música que mais ouço, há algum álbum que se destaque muito dos demais?
É importante frisar que há limitações nesse conjunto de dados. Por exemplo, apenas os 5000 álbuns com mais reviews estão disponíveis para análise. Embora não sejam todos os álbuns lançados no mundo, é razoável acreditar que a parte mais importante deles esteja disponível.
E aí surge o maior problema deste conjunto de dados. Por serem dados obtidos a partir de um site usado predominantemente por falantes de inglês, muitos artistas do sul global não estão bem representados. Por exemplo, Caetano Veloso aparece com apenas dois discos na lista, o que é muito pouco. O principal trio de rock argentino (Luis Alberto Spinetta, Charly Garcia e Fito Paez) sequer aparecem entre esses 5000 álbuns. Portanto, é algo que deve ser levado em conta por aqui.
De todo modo, seguem os passos da análise que fiz. Meu primeiro passo foi ler os dados:
library(tidyverse)
theme_set(theme_minimal())
library(ggrepel)
rym <-
read_csv(file = "dados/rate_your_music.csv") |>
select(-1)
Em seguida, contei o número de álbuns por gênero:
rym |>
count(primary_genres) |>
arrange(desc(n))
## # A tibble: 2,246 × 2
## primary_genres n
## <chr> <int>
## 1 Alternative Rock 80
## 2 Hard Rock 77
## 3 Indie Rock 71
## 4 Pop Rock 62
## 5 Heavy Metal 57
## 6 Progressive Rock 57
## 7 Thrash Metal 43
## 8 Post-Rock 41
## 9 Death Metal 40
## 10 Post-Punk 40
## # ℹ 2,236 more rows
O problema em usar a coluna primary_genres é que há casos em que os álbuns estão classificados em mais de um gênero. Por exemplo:
rym |>
count(primary_genres) |>
arrange(desc(n)) |>
filter(grepl("Alternative Rock", primary_genres))
## # A tibble: 120 × 2
## primary_genres n
## <chr> <int>
## 1 Alternative Rock 80
## 2 Alternative Rock, Pop Rock 16
## 3 Pop Rock, Alternative Rock 12
## 4 Power Pop, Alternative Rock 10
## 5 Alternative Rock, Art Rock 9
## 6 Alternative Rock, Indie Rock 8
## 7 Alternative Metal, Alternative Rock 7
## 8 Alternative Rock, Post-Grunge 6
## 9 Grunge, Alternative Rock 6
## 10 Indie Rock, Alternative Rock 6
## # ℹ 110 more rows
Por iso, criei uma nova coluna chamada genre_1 em que mantive apenas a primeira ocorrência encontrada em cada um dos primary_genres. Como os gêneros não estão em ordem alfabética, imaginei que o primeiro gênero citado é o que mais predomina no álbum.
rym <-
rym |>
separate(primary_genres, into = "genre_1", extra = "drop", remove = FALSE, sep = ",")
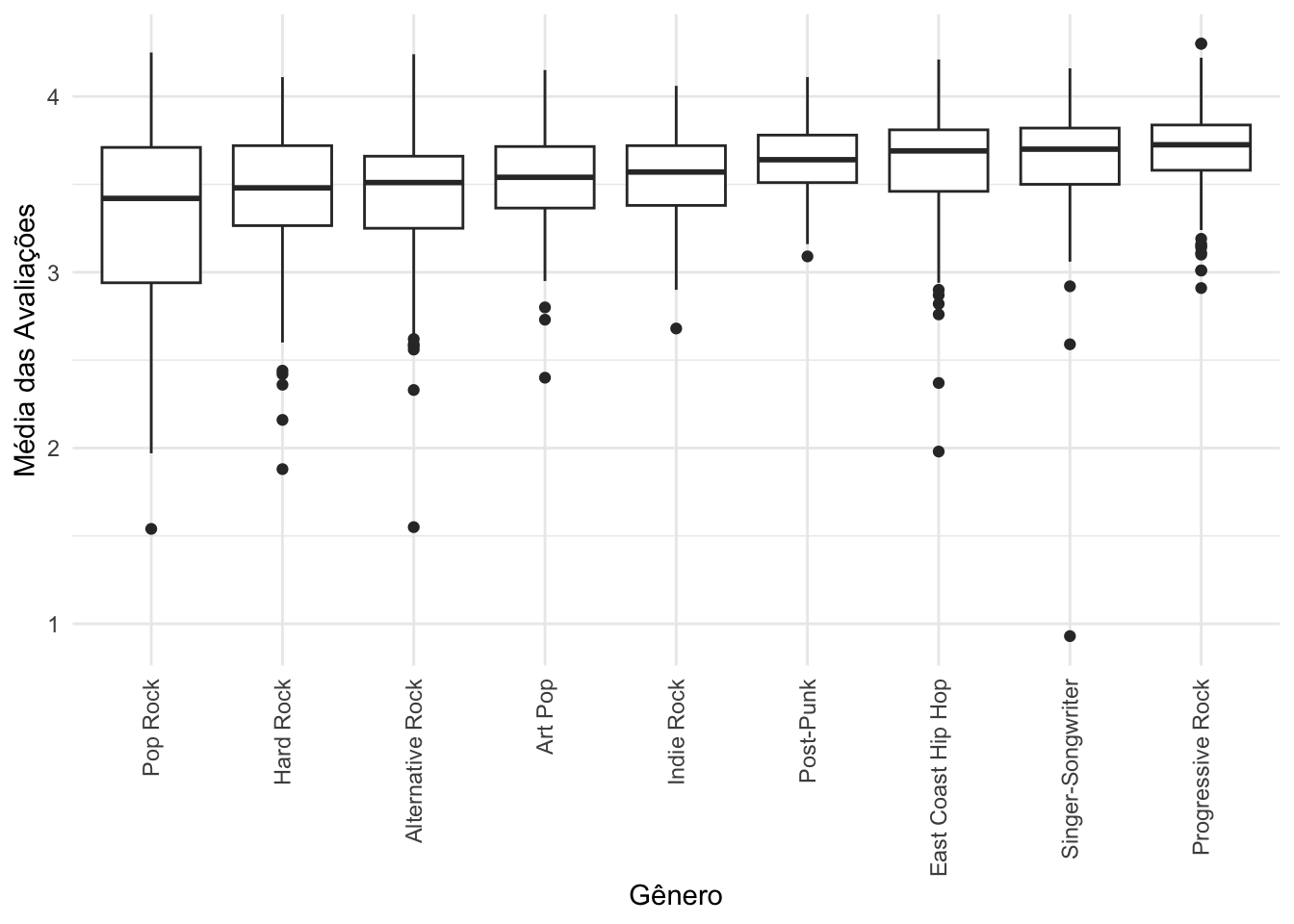
Assim, os nove gêneros com mais reviews no Rate Your Music, com mais do que 100 álbuns cada um, são os seguintes:
rym <-
rym |>
group_by(genre_1) |>
mutate(n = n()) |>
arrange(desc(n)) |>
ungroup()
rym |>
filter(n > 100) |>
ggplot(aes(x = reorder(genre_1, avg_rating, median), y = avg_rating)) +
geom_boxplot() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
labs(x = "Gênero", y = "Média das Avaliações")
Em seguida, a função is_outlier encontra quais observações são outliers. Em particular, aplico isso em cada gênero, de modo a encontrar os outliers para cada um deles.
is_outlier <- function(x) {
return(x < quantile(x, 0.25) - 1.5 * IQR(x) | x > quantile(x, 0.75) + 1.5 * IQR(x))
}
rym <-
rym |>
mutate(label = paste(artist_name, release_name, sep = " - ")) |>
group_by(genre_1) |>
mutate(is_outlier = ifelse(is_outlier(avg_rating), avg_rating, as.numeric(NA))) |>
ungroup()
rym$label[which(is.na(rym$is_outlier))] <- NA
rym |>
filter(n > 100) |>
ggplot(aes(x = reorder(genre_1, avg_rating, median), y = avg_rating)) +
geom_boxplot() +
geom_text_repel(aes(label = label), nudge_y=0.05) +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
labs(x = "Gênero", y = "Média das Avaliações")
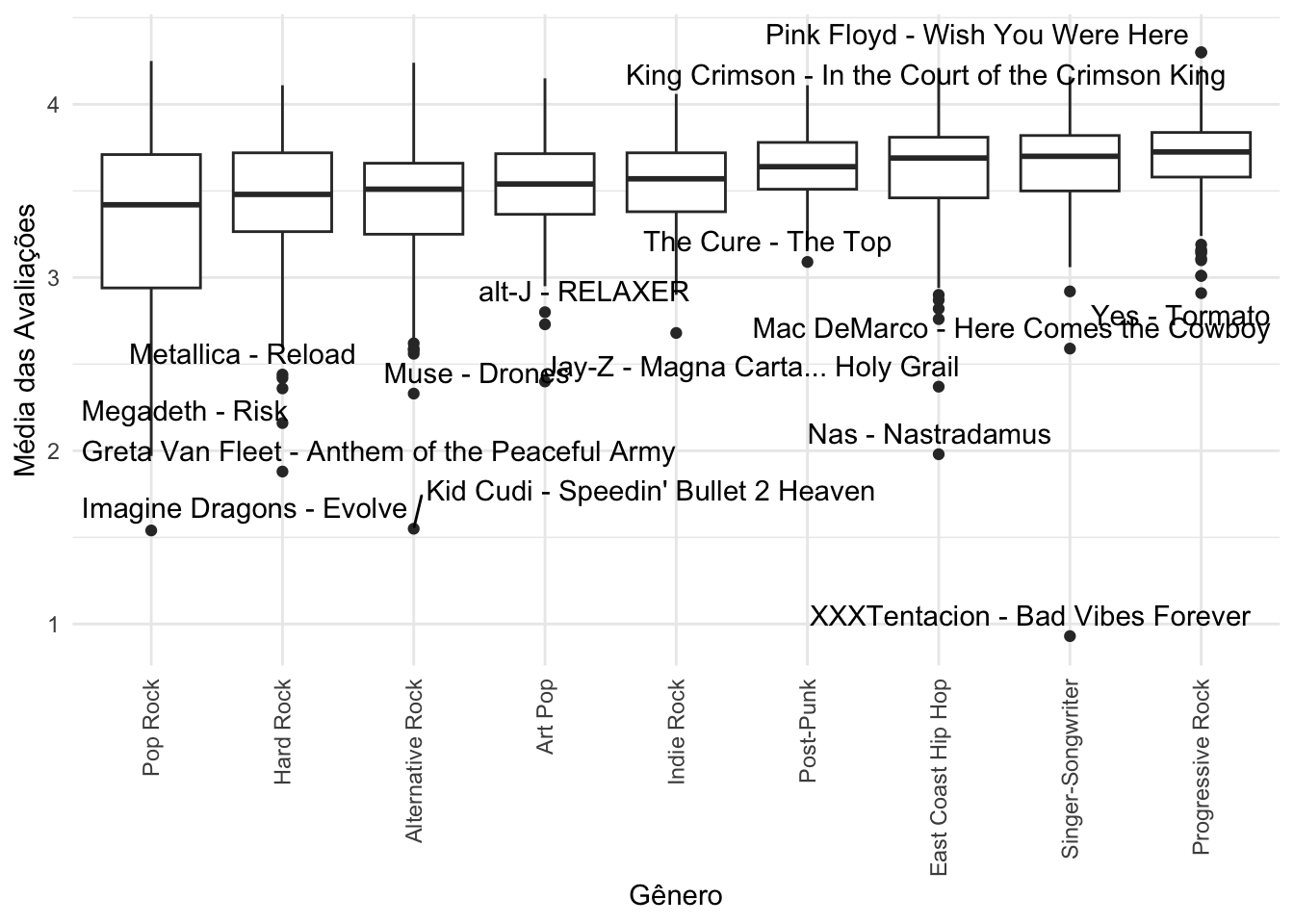
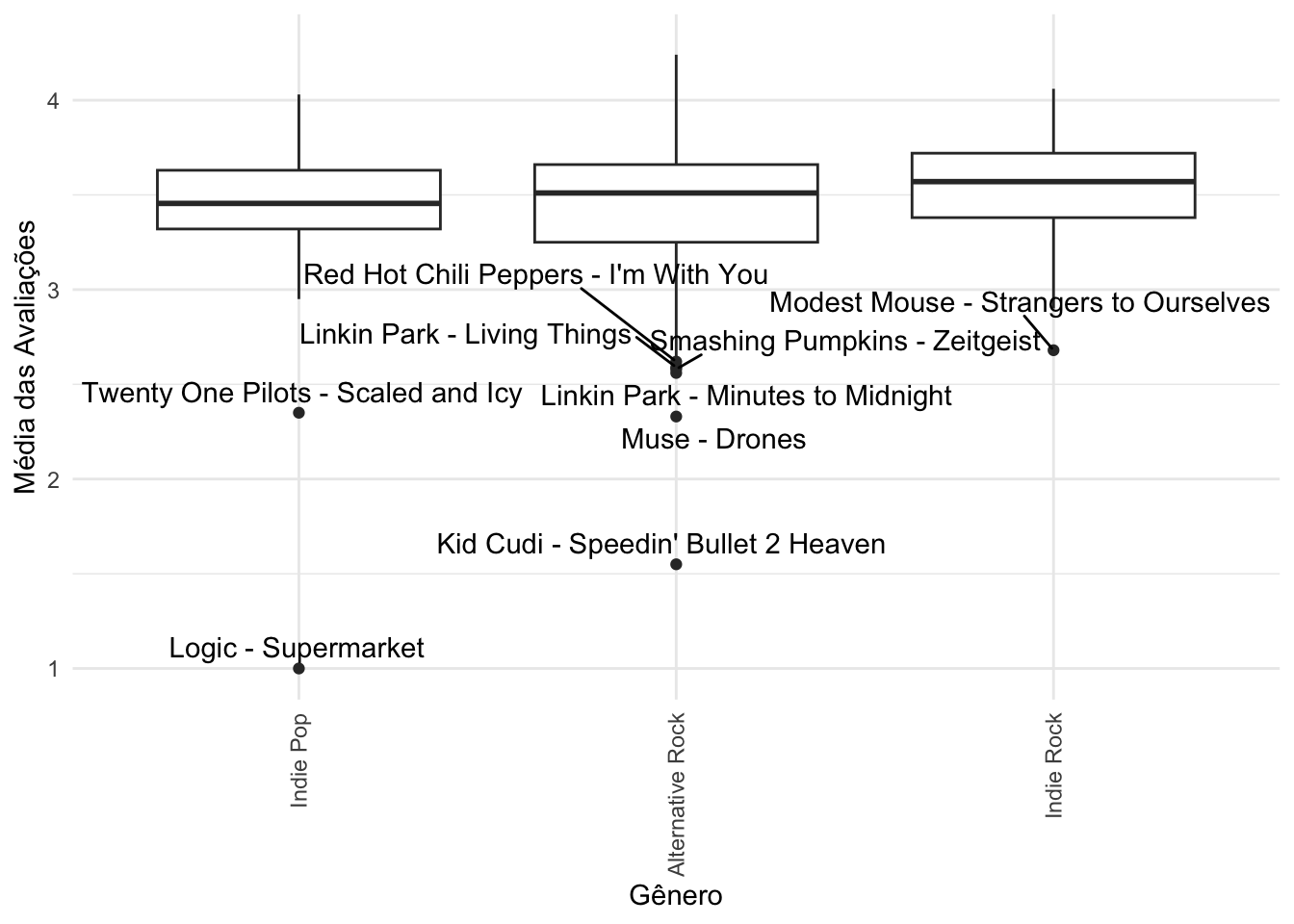
Entretanto, dessa forma fica bem difícil visualizar os nomes de quais álbuns são os de maior destaque em cada gênero. Para resolver isso, limitei o número de gêneros a apenas três em cada boxplot.
rym |>
filter(genre_1 %in% c("Alternative Rock", "Indie Pop", "Indie Rock")) |>
ggplot(aes(x = reorder(genre_1, avg_rating, median), y = avg_rating)) +
geom_boxplot() +
geom_text_repel(aes(label = label), na.rm = TRUE, nudge_y=0.05) +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
labs(x = "Gênero", y = "Média das Avaliações")
rym |>
filter(genre_1 %in% c("Cool Jazz", "Post-Punk", "Punk Rock")) |>
ggplot(aes(x = reorder(genre_1, avg_rating, median), y = avg_rating)) +
geom_boxplot() +
geom_text_repel(aes(label = label), na.rm = TRUE, nudge_y=0.05) +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
labs(x = "Gênero", y = "Média das Avaliações")
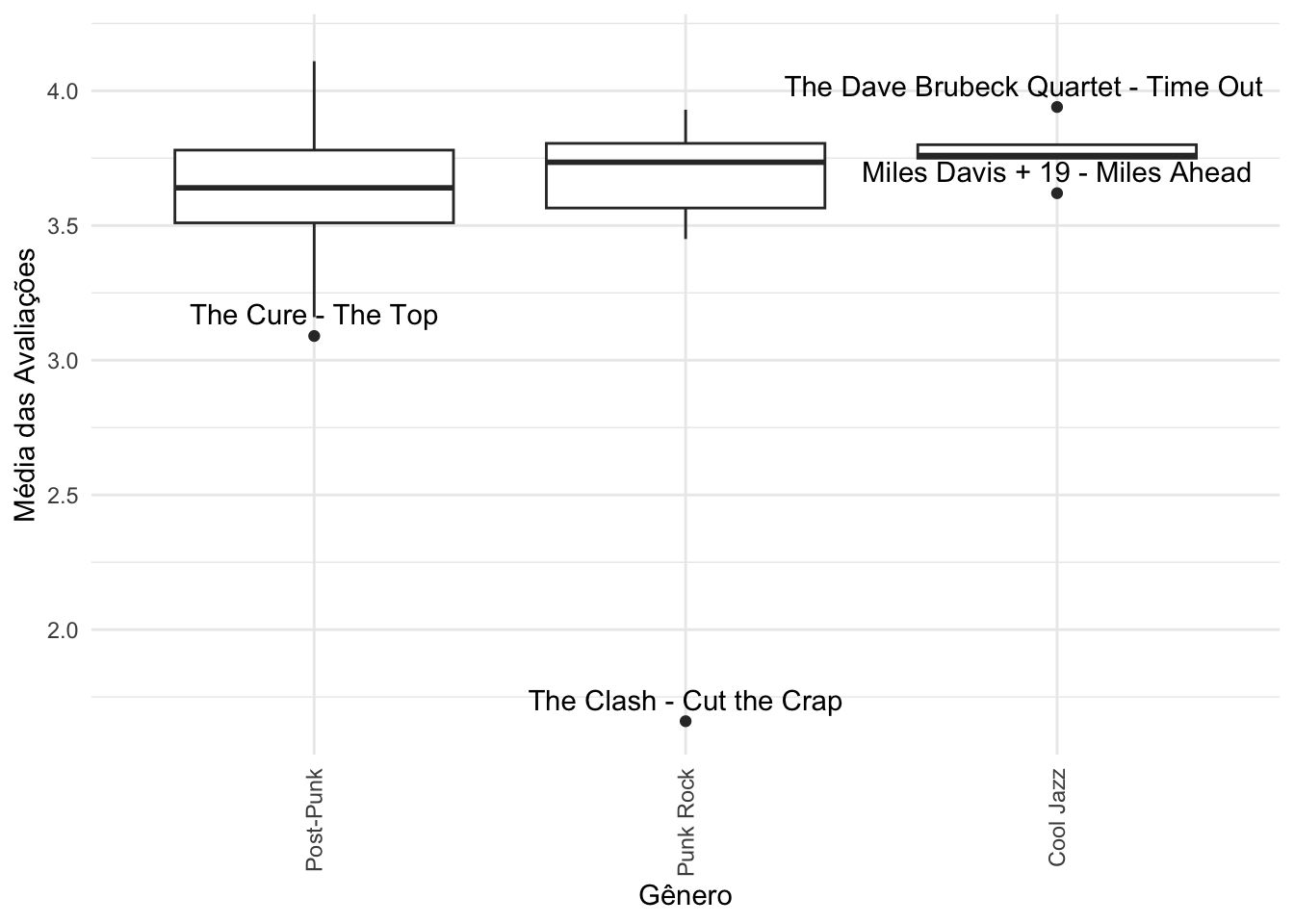
Desta forma, o único álbum que se destaca positivamente dentro dos gêneros que mais gosto é Time Out, do Dvave Brubeck. Não à toa, é um dos meus discos de jazz favoritos.