Motivação Link para o cabeçalho
Como exercício de programação, decidi verificar quantas citações cada um dos três personagens principais de Dom Casmurro (Bentinho, Capitu e Escobar) tiveram em cada capítulo da obra. A ideia é contar as ocorrências de cada nome em cada capítulo e, a partir disso, fazer o somatório geral desses valores.
Obtenção e Preparação dos Dados Link para o cabeçalho
O primeiro passo foi utilizar o Projeto Gutenberg para obter os dados. Isso permite que eu tenha acesso a uma versão razoavelmente oficial da obra, mas principalmente gratuita e em formato txt.
library(tidyverse)
theme_set(theme_minimal())
# devtools::install_github("ropensci/gutenbergr")
library(gutenbergr)
library(tidytext)
library(stringi)
# encontrar o codigo de dom casmurro
gutenberg_metadata |>
filter(title == "Dom Casmurro")
## # A tibble: 1 × 8
## gutenberg_id title author gutenberg_author_id language gutenberg_bookshelf
## <int> <chr> <chr> <int> <fct> <chr>
## 1 55752 Dom Casm… Macha… 9685 pt Browsing: Literatu…
## # ℹ 2 more variables: rights <fct>, has_text <lgl>
# baixar o arquivo correspondente
dom_casmurro_gutenberg <- gutenberg_download(55752)
# retirando o indice ao final
dom_casmurro_gutenberg <- head(dom_casmurro_gutenberg, -150)
A partir disso, é necessário separar o texto. Originalmente ele vem em parágrafos e é necessário separá-lo em palavras, removendo acentos e deixando todas as palavras em letras minúsculas:
dom_casmurro <-
dom_casmurro_gutenberg |>
unnest_tokens(word, text) |>
mutate(word = stri_trans_general(str = word, id = "Latin-ASCII")) |>
mutate(word = tolower(word))
Entretanto, algumas dessas palavras são marcadores de capítulos. Capítulos esses que estão em numeração romana. Para isso, foi necessário converter estes valores para numeração arábica:
dom_casmurro <-
dom_casmurro |>
mutate(capitulo = as.roman(word)) |>
mutate(capitulo = as.numeric(capitulo))
Em seguida, veio a parte mais complicada. Foi preciso criar uma coluna extra, chamada capitulo_novo, para manter a identificação de cada palavra. Isto é, todas as palavras do Capítulo I (1, na verdade), terão o valor 1 ao seu lado. Todas as palavras do Capítulo II (2), terão o valor 2 ao seu lado e assim por diante, para todos os capítulos (são 148, para quem ficou curioso).
Ao fim, renomeei capitulo_novo para capitulo, de modo a evitar confusões.
# encontrar o número do capítulo
capitulo <- dom_casmurro$capitulo
capitulo[is.na(capitulo)] <- 0
capitulo_novo <- 0
i <- 0
for (j in 1:length(capitulo)){
if (capitulo[j] == i){
capitulo_novo[j] <- i
i <- i + 1
}
}
capitulo_novo <- data.frame(capitulo = c(capitulo_novo, rep(NA, length(capitulo)-length(capitulo_novo))))
rm(capitulo)
dom_casmurro <-
dom_casmurro |>
select(-capitulo) |>
bind_cols(capitulo_novo) |>
fill(capitulo) |>
filter(capitulo > 0)
Visualização Link para o cabeçalho
Com os dados preparados, basta contar as ocorrências de cada personagem no livro. Em particular, Bentinho e Casmurro foram considerados como sendo o mesmo personagem.
personagens <-
dom_casmurro |>
mutate(word = ifelse(word == "casmurro", "bentinho", word)) |>
filter(word %in% c("bentinho", "capitu", "escobar"))
personagens_por_capitulo <-
personagens |>
group_by(capitulo) |>
count(word)
personagens_por_capitulo <-
expand_grid(capitulo = 1:max(dom_casmurro$capitulo),
word = c("bentinho", "capitu", "escobar")) |>
left_join(personagens_por_capitulo) |>
replace_na(list(n = 0)) |>
group_by(word) |>
mutate(n_acumulado = cumsum(n)) |>
mutate(word = str_to_title(word)) |>
mutate(word = ifelse(word == "Bentinho", "Bentinho/\nDom Casmurro", word))
Com as contagens feitas, basta fazer o gráfico:
ggplot(personagens_por_capitulo, aes(x = capitulo, y = n_acumulado, colour = word)) +
geom_line() +
scale_colour_viridis_d() +
labs(x = "Capítulo",
y = "Quantidade de Citações Acumuladas",
colour = "Personagem",
title = "Comparação de Citações entre os\nPersonagens Principais de Dom Casmurro",
caption = "marcusnunes.me")
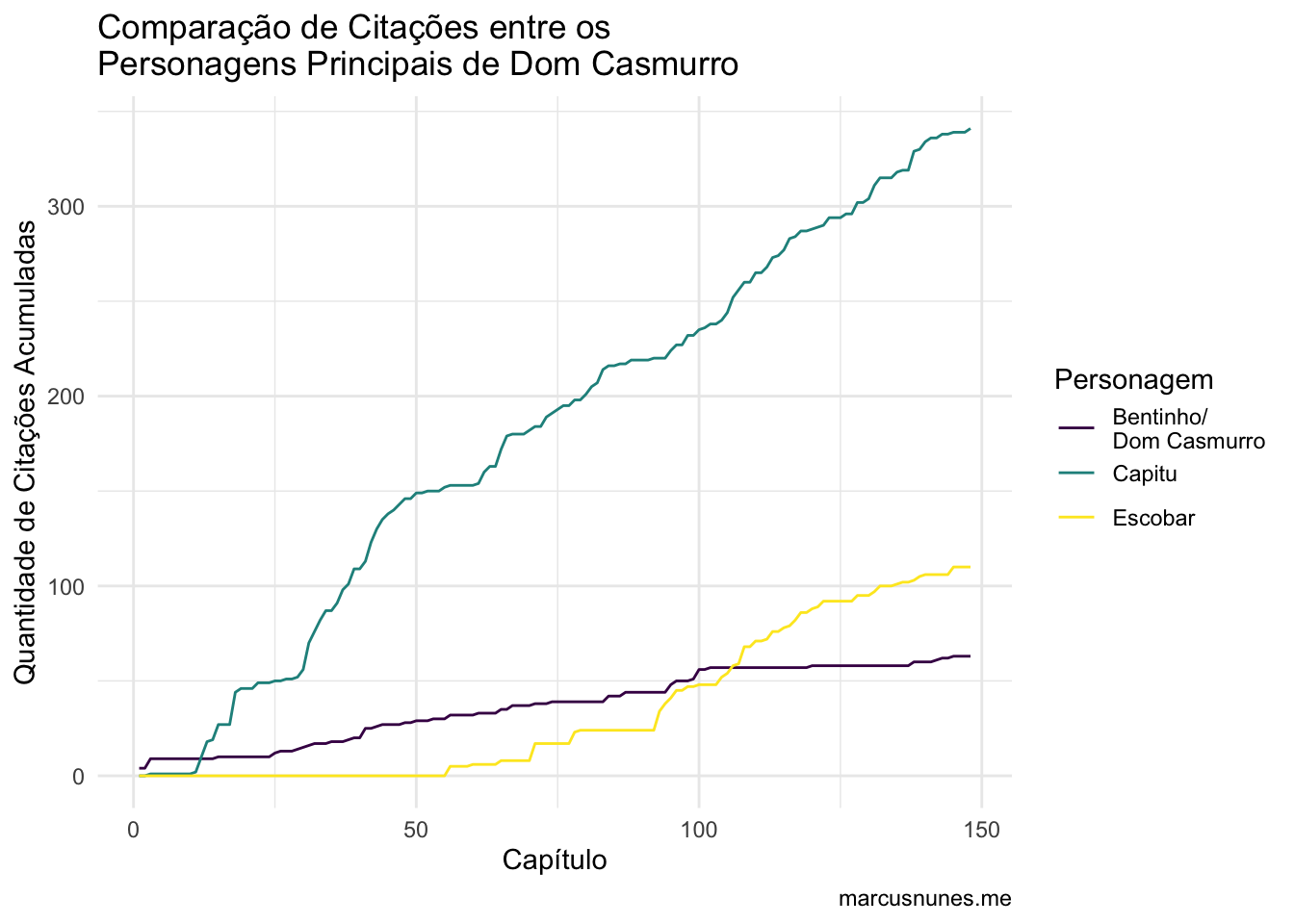
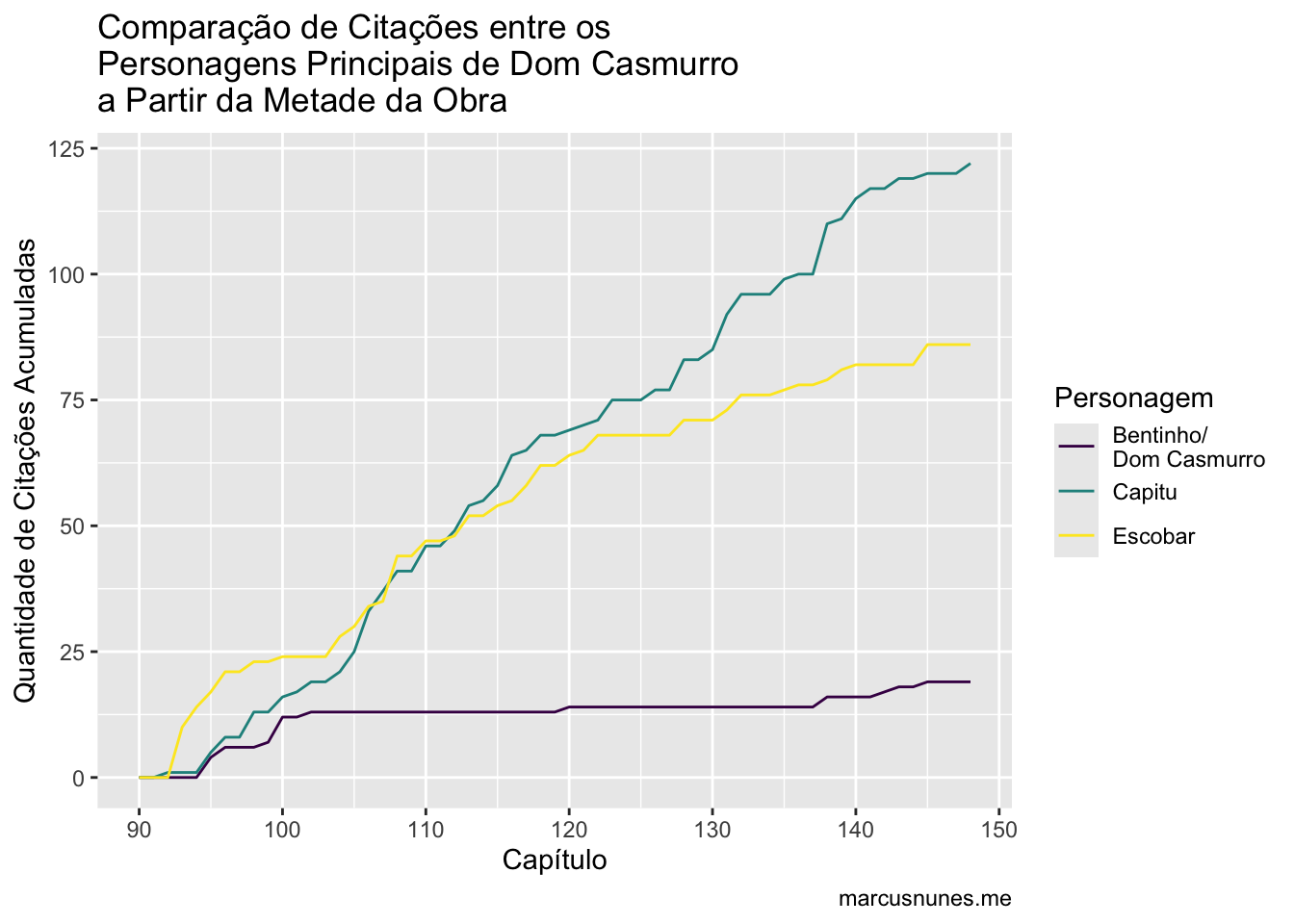
Claramente, Capitu é a personagem mais citada, o que não é um absurdo imaginar. Mas note como próximo ao capítulo 100 há um salto no número de citação de Escobar. Se refizermos o gráfico a partir do capítulo 90, Capitu e Escobar possuem um número de citações bem similar.
personagens_por_capitulo |>
filter(capitulo >= 90) |>
mutate(n_acumulado = cumsum(n)) |>
ggplot(aes(x = capitulo, y = n_acumulado, colour = word)) +
geom_line() +
scale_colour_viridis_d() +
labs(x = "Capítulo",
y = "Quantidade de Citações Acumuladas",
colour = "Personagem",
title = "Comparação de Citações entre os\nPersonagens Principais de Dom Casmurro\na Partir da Metade da Obra",
caption = "marcusnunes.me")