Sou maior de idade, pago meus impostos e contribuo para o PIB. Portanto, nada me impede de ocasionalmente beber uma ou outra cerveja em meus momentos de lazer. Embora eu tenha as minhas preferências pessoais neste assunto, estive pensando qual seria a opinião geral do brasileiro a respeito das cervejas disponíveis no mercado. De acordo com o G1, cada brasileiro consumiu, em média, 60,7 litros de suco de cevada em 2017, o que serve como indicativo do quanto o povo daqui curte uma ampola (ou talvez mais) deste diurético.
Este nível de consumo de cerveja demonstra o interesse da população do nosso país nesta bebida. Assim, acho interessante verificar como os brasileiros avaliam as cervejas consumidas aqui no país. Em vez de tomar uma amostra e sair na rua entrevistando pessoas a este respeito, resolvi utilizar a tecnologia a meu favor.
Existe uma técnica computacional muito utilizada chamada web scraping (raspagem da web). Esta técnica consiste em vasculhar a internet atrás de informações. É o que o Google, por exemplo, usar para indexar os sites em seu mecanismo de busca. Um algoritmo visita automaticamente várias páginas e coleta apenas os dados que são interessantes, a fim de criar um banco de dados para análise ou consulta posterior.
Portanto, se eu conseguisse encontrar algum lugar na internet com as opiniões dos brasileiros sobre cerveja, eu poderia compilá-las em um local e descobrir o que o povo do país pensa sobre os estilos da bebida.
É aí que entra o site Brejas. Ele é uma comunidade alimentada por usuários que consomem as mais variadas cervejas e as avalia de acordo com as seguintes características:
<li>Avaliação Geral</li>
<li>Aroma</li>
<li>Aparência</li>
<li>Sabor</li>
<li>Sensação</li>
<li>Conjunto</li>
Estas avaliações são convertidas em estrelas e são exibidas de forma aberta na internet:
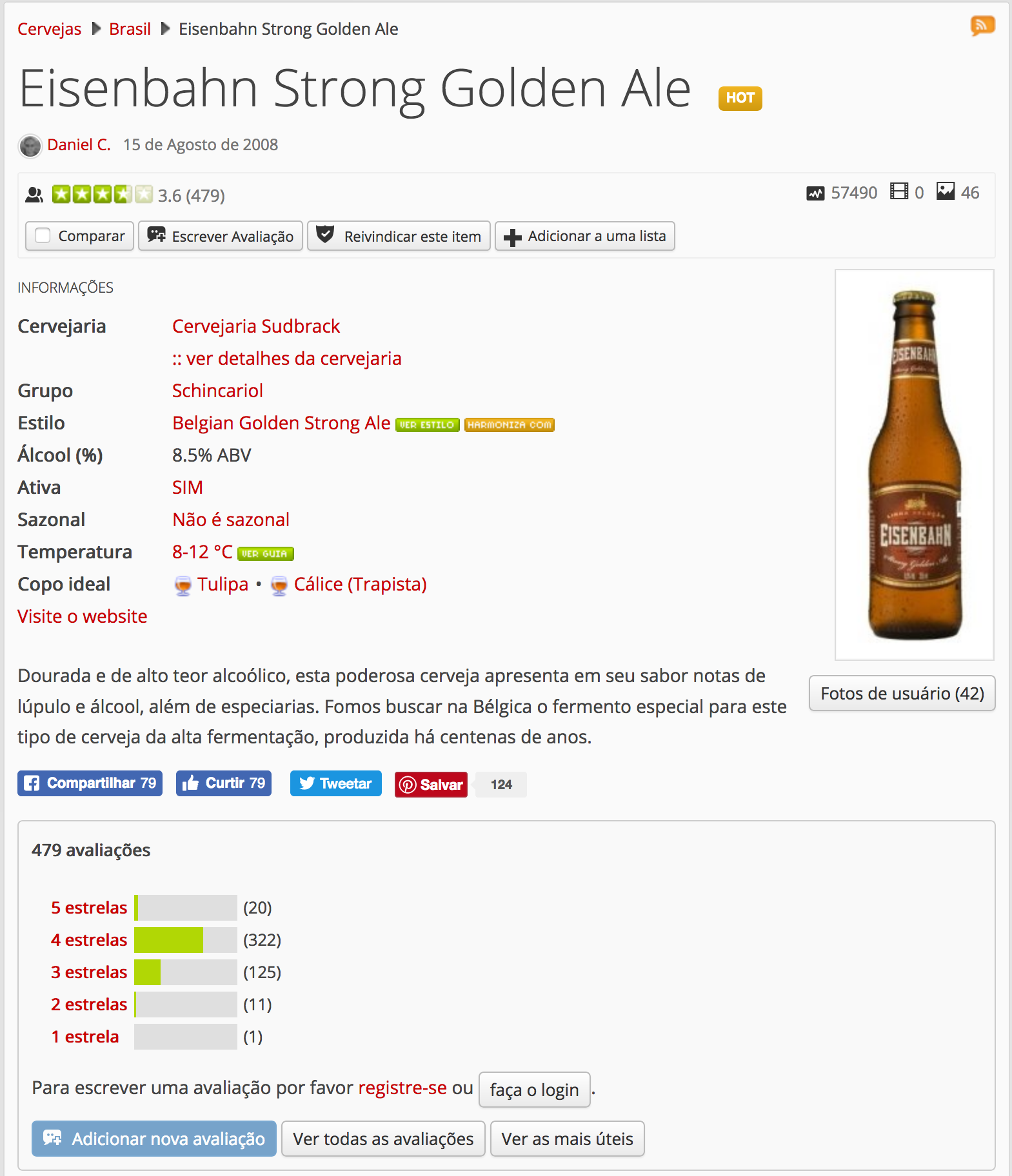
Link para a página original da cerveja acima.
Pensando nisso, criei um código no capaz de entrar no site brejas.com.br e baixar as cervejas com o maior número de avaliações recebidas. Por padrão, meu programa baixa as 1000 cervejas com maior número de avaliações. Dividi meu código em três partes, que descrevo abaixo.
A primeira parte do código é uma função chamada scrap, criada justamente para encontrar os links das cervejas mais avaliadas. Como estes links não estão todos na mesma página, é necessário navegar no Brejas para que esta informação seja encontrada.
# funcao para encontrar os links das cervejas com mais
# avaliacoes no brejas.com.br
scrap <- function(url){
pagina <- read_html(url)
# filtragem dos links
links <- html_attr(html_nodes(pagina, "a"), "href")
links <- links[grep("/cerveja/", links)]
links <- links[grep("#", links, invert=TRUE)]
links <- links[grep("www", links, invert=TRUE)]
# manter apenas os que mais se repetem
links <- names(sort(table(links), decreasing=TRUE)[1:10])
# criar os links completos
links <- paste("http://www.brejas.com.br", links, sep="")
return(links)
}A segunda parte do código depende da primeira. A função cerveja toma os links obtidos anteriormente e baixa as informações que servem para avaliar as cervejas.
# funcao para extrair as informacoes de uma cerveja
# do brejas.com.br a partir de um link
cerveja <- function(url){
pagina <- read_html(url)
# nome da cerveja
nome <- pagina %>%
html_nodes(xpath="/html/body/div[2]/div[2]/div/main/article/div/div/h1/span[1]") %>%
html_text()
# informacoes
informacoes <- pagina %>%
html_nodes(xpath="/html/body/div[2]/div[2]/div/main/article/div/div/div[8]/div") %>%
html_text()
if (length(informacoes)==0){
informacoes <- pagina %>%
html_nodes(xpath="/html/body/div[2]/div[2]/div/main/article/div/div/div[7]/div") %>%
html_text()
}
cervejaria <- gsub("InformaçõesCervejaria", "", strsplit(informacoes, split="Grupo")[[1]][1])
grupo <- strsplit(strsplit(informacoes, split="Grupo")[[1]][2], split="Estilo")[[1]][1]
estilo <- strsplit(strsplit(informacoes, split="Estilo")[[1]][2], split="Álcool")[[1]][1]
ativa <- strsplit(strsplit(informacoes, split="Ativa")[[1]][2], split="Sazonal")[[1]][1]
sazonal <- strsplit(strsplit(informacoes, split="Sazonal")[[1]][2], split="Temperatura")[[1]][1]
copo <- strsplit(strsplit(informacoes, split="Copo ideal")[[1]][2], split="Visite")[[1]][1]
numeros <- str_extract_all(informacoes, "\\(?[0-9,.]+\\)?")[[1]]
numeros <- numeros[grep(",", numeros, invert=TRUE)]
numeros <- as.numeric(numeros)
alcool <- numeros[1]
t.min <- numeros[2]
t.max <- numeros[3]
# scores
dados <- pagina %>%
html_nodes(xpath="/html/body/div[2]/div[2]/div/main/article/div/div/div[15]/div[3]/div/div[1]/div[2]/div/div[1]") %>%
html_text()
if (length(dados) == 0){
dados <- pagina %>%
html_nodes(xpath="/html/body/div[2]/div[2]/div/main/article/div/div/div[16]/div[3]/div/div[1]/div[2]/div/div[1]") %>%
html_text()
}
if (length(dados) == 0) {
resultado <- data.frame(Nome=nome,
Cervejaria=cervejaria,
Grupo=grupo,
Estilo=estilo,
Alcool=alcool,
Ativa=ativa,
Sazonal=sazonal,
Minima=t.min,
Maxima=t.max,
Copo=copo,
Geral=NA,
Aroma=NA,
Aparencia=NA,
Sabor=NA,
Sensacao=NA,
Conjunto=NA,
Votos=NA)
} else {
# regex para extrair apenas os numeros
avaliacao <- str_extract_all(dados, "\\(?[0-9,.]+\\)?")[[1]]
avaliacao <- avaliacao[c(1, 2, 5, 8, 11, 14, 4)]
avaliacao <- as.numeric(gsub("\\((.+)\\)","\\1", avaliacao))#/c(1, 10, 5, 20, 5, 10, 1)
# organizar as informacoes
resultado <- data.frame(Nome=nome,
Cervejaria=cervejaria,
Grupo=grupo,
Estilo=estilo,
Alcool=alcool,
Ativa=ativa,
Sazonal=sazonal,
Minima=t.min,
Maxima=t.max,
Copo=copo,
Geral=avaliacao[1],
Aroma=avaliacao[2],
Aparencia=avaliacao[3],
Sabor=avaliacao[4],
Sensacao=avaliacao[5],
Conjunto=avaliacao[6],
Votos=avaliacao[7])
}
return(resultado)
}Por fim, é preciso juntar estas duas funções para que tudo dê certo:
# pacotes necessarios
library(rvest)
library(httr)
library(stringr)
library(tidyverse)
# funcoes para obter os dados
source("cerveja.R")
source("scrap.R")
# funcoes para obter os dados
source("cerveja.R")
source("scrap.R")
####################################
### baixar os dados para analise ###
####################################
# baixar os links das 10*k cervejas mais avaliadas
links <- scrap("http://www.brejas.com.br/cerveja/mais-avaliadas?page=1")
k <- 100
for (j in 2:k){
url <- paste("http://www.brejas.com.br/cerveja/mais-avaliadas?page=", j, sep="")
links <- c(links, scrap(url))
}
links <- sort(links)
dados <- cerveja(links[1])
for (j in links[c(-1)]){
dados <- rbind(dados, cerveja(j))
}
# remove espacos ao final dos nomes
dados$Estilo <- trimws(dados$Estilo, "right")Meu computador levou 42 minutos para baixar os dados de 1000 cervejas. Ou seja, na média, as informações de cada cerveja levaram aproximadamente 2,5 segundos para serem coletadas. Talvez seja um desempenho um pouco lento, mas não é nada mal para um código não muito otimizado.
Agora que os dados foram baixados, basta proceder com a análise. Mas isto é um papo para um outro post.
Os códigos usados para obter os dados e para a análise realizada estão no meu github.
Este post foi inspirado por um trabalho realizado pela Kaylin Walker.
Dê um like na fanpage do blog e fique sabendo das próximas atualizações.