Introdução Link para o cabeçalho
Enquanto orientador acadêmico, uma coisa que gosto de fazer é analisar o quanto os alunos andam produzindo a cada reunião. Embora eu já tivesse uma boa ideia do quanto cada um deles estava produzindo, eu não possuía um quantitativo exato disso. Bem, eu não tinha até hoje.
Neste post vou mostrar a minha técnica para isso, exibindo o comportamento exato de como os alunos estão se saindo. Logicamente, os relatórios que analiso neste post são fictícios, para evitar expor desnecessariamente meus orientandos.
Organização dos Arquivos Link para o cabeçalho
O que faço com meus alunos é pedir uma versão atualizada da monografia (ou dissertação ou tese) toda semana. Assim, posso guardar cada uma das versões e analisá-las depois de um tempo. Para que estes arquivos sejam analisáveis, eu os salvo no formato yyyy-mm-dd.pdf. Ou seja, se o aluno enviou o arquivo em 13 de janeiro de 2022, eu salvarei este arquivo como 2022-01-13.pdf.
Algoritmo Link para o cabeçalho
Com a série de arquivos salvos, basta que eu os importe no R, extraia o texto dos pdfs e depois conte os números de
- caracteres
- palavras
- páginas
Isso tudo está implementado abaixo:
# pacotes necessarios
library(pdftools)
## Using poppler version 23.04.0
library(tidyverse)
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.0 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
theme_set(theme_bw() +
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)))
library(stringi)
library(lubridate)
# lista de arquivos
arquivos <- list.files("relatorios/")
# limpeza da lista de arquivos
# a expressao regular abaixo mantem apenas
# os arquivos com nome no formato yyyy-mm-dd.pdf
arquivos <- grep("^\\d{4}-\\d{2}-\\d{2}.pdf", arquivos, value = TRUE)
arquivos <- paste("relatorios/", arquivos, sep = "")
# funcao para ler os arquivos pdf, extrair o texto
# e limpar eventuais sujeiras
limpeza <- function(x){
x <- pdf_text(x)
paginas <- length(x)
x <- x %>%
paste(., collapse = " ") %>%
str_remove_all("\\n") %>%
str_remove_all(" \\. ")
return(c(nchar(x),
stri_count(x, regex="\\S+"),
paginas))
}
# aplica a funcao limpeza e formata o data frame final
dados <- arquivos %>%
map(limpeza) %>%
do.call(rbind.data.frame, .) %>%
bind_cols(arquivos) %>%
select(data = 4, caracteres = 1, palavras = 2, paginas = 3) %>%
mutate(data = ymd(gsub("\\.pdf", "", data)))
## New names:
## • `` -> `...4`
# graficos
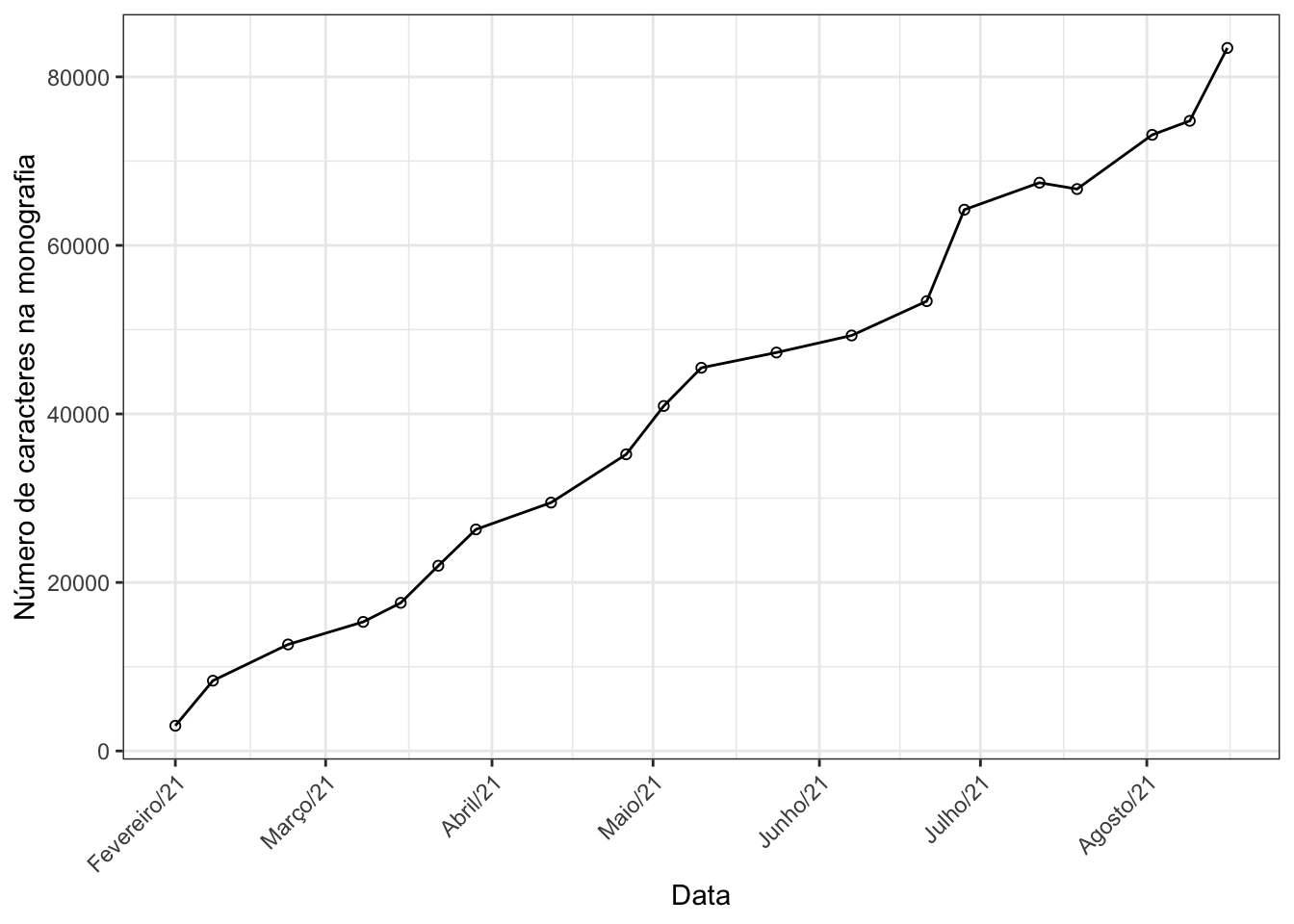
ggplot(dados, aes(x = data, y = caracteres)) +
geom_line() +
geom_point(pch = 1) +
labs(x = "Data", y = "Número de caracteres na monografia") +
scale_x_date(breaks = "1 month", date_labels = "%B/%y")
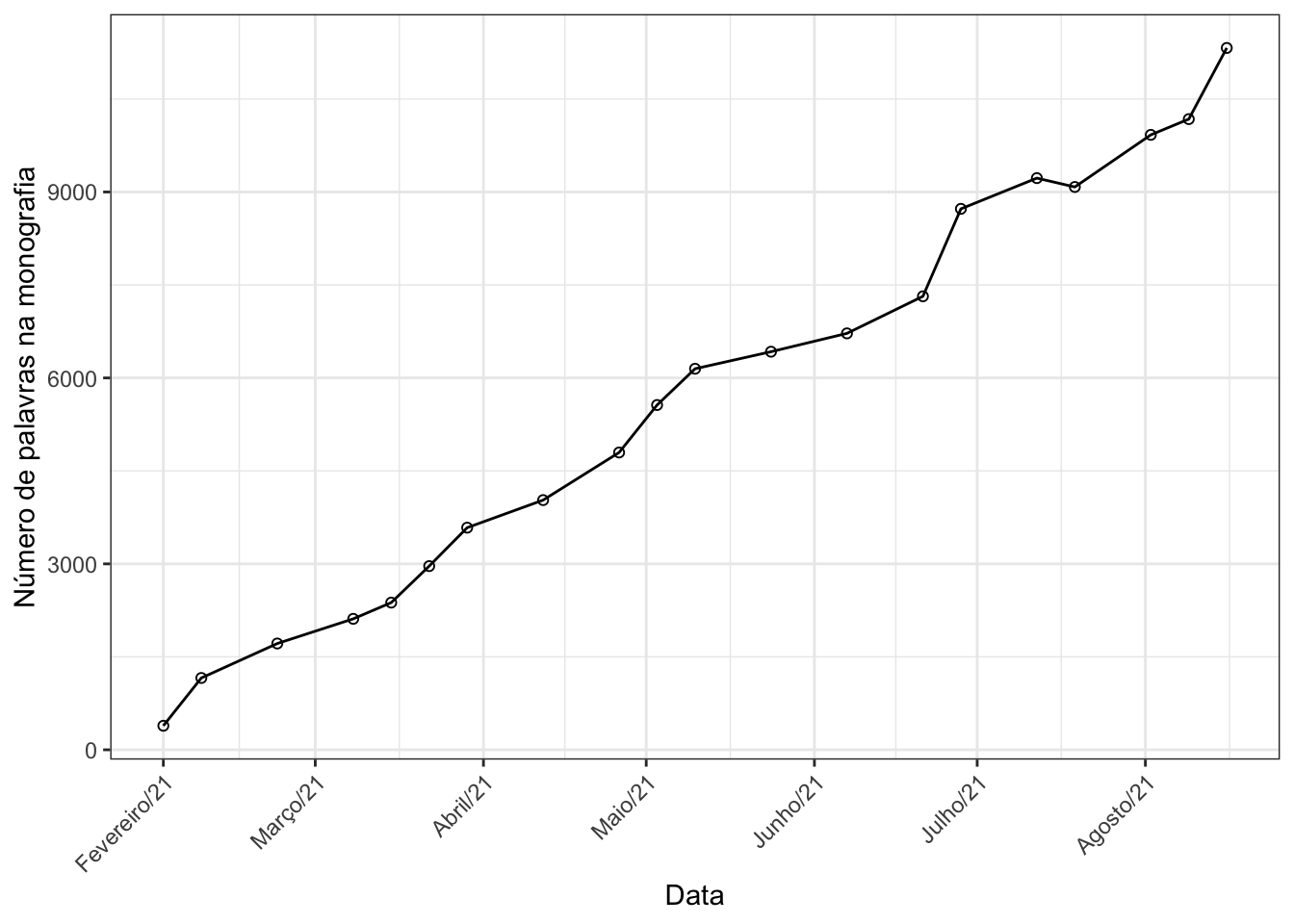
ggplot(dados, aes(x = data, y = palavras)) +
geom_line() +
geom_point(pch = 1) +
labs(x = "Data", y = "Número de palavras na monografia") +
scale_x_date(breaks = "1 month", date_labels = "%B/%y")
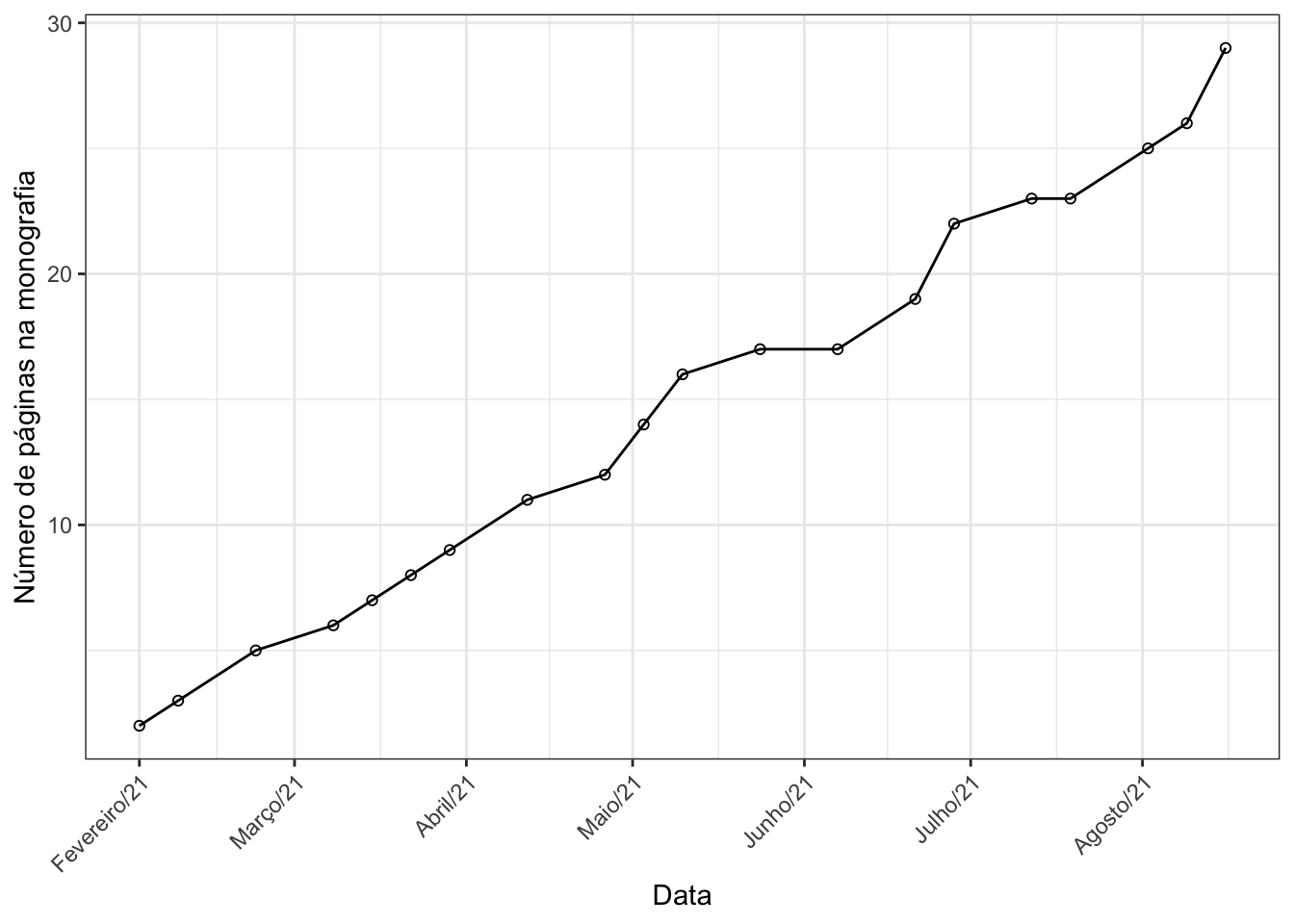
ggplot(dados, aes(x = data, y = paginas)) +
geom_line() +
geom_point(pch = 1) +
labs(x = "Data", y = "Número de páginas na monografia") +
scale_x_date(breaks = "1 month", date_labels = "%B/%y")
Este exemplo pode ser reproduzido com o código disponível no github.