Introdução Link para o cabeçalho
Analisar sentimentos em texto é uma das coisas que sempre desejei aprender a fazer. Ao descobrir o post Bojack Horseman and Tidy Data Principles (Part 1) senti que era o momento de dar o pontapé inicial no assunto. Mas em vez de simplesmente reaplicar aquilo que o meu texto inspirador fez, decidi ir além, comparando duas séries de TV que gosto bastante.
Para tal, escolhi Bojack Horseman e Brooklyn Nine-Nine para a empreitada. Optei pelas duas por uma série de motivos. O principal deles, como dito anteriormente, é o fato de eu gostar de ambas. Além disso, as duas séries são consideradas sitcoms, o que as coloca no mesmo gênero televisivo. Não obstante, são séries contemporâneas: Bojack Horseman estreou em 2014, enquanto Brooklyn Nine-Nine é apenas um ano mais velha. Assm, decidi me concentrar nas cinco primeiras temporadas de cada seriado.
O que as difere são os temas abordados. Enquanto Bojack Horseman é uma série brutalmente triste, que explora a relação do protagonista com a sua depressão, Brooklyn Nine-Nine aposta em piadas leves e temas como inclusão para contar a sua história.
Assim, a minha hipótese é que Bojack Horseman use sentimentos mais negativos em seus diálogos, enquanto Brooklyn Nine-Nine seja uma série mais positiva.
Obtenção dos Dados Link para o cabeçalho
O ideal seria utilizar os roteiros dos seriados como base para a minha análise. Mas isto so mostrou impossível, pois desejo encontrar resultados em português. Portanto, decidi utilizar as legendas traduzidas para fazer a minha análise. Por sorte, o site Legendas TV possui todas as legendas das cinco primeiras temporadas destes seriados. Como estas legendas estão organizadas em um arquivo único por temporada, o trabalho de baixá-las tornou-se bem menor.
Tratamento e Análise dos Dados Link para o cabeçalho
Palavras Mais Frequentes Link para o cabeçalho
A primeira parte da análise é carregar os pacotes necessários para realizá-la. Note que o pacote subtools está hospedado no GitHub, o que implica que não basta rodar install.packages(subtools) para que ele seja instalado.
# pacotes necessarios
library(subtools) # devtools::install_github("fkeck/subtools")
library(tm)
library(tidyverse)
theme_set(theme_bw())
library(gridExtra)
library(reshape2)
Como cada episódio dos seriados está armazenado em um arquivo .srt diferente, é necessário ter uma forma prática de ler todos estes arquivos de uma vez. A função subtools::read.subtitles.serie é perfeita para isso, pois além de ler todos os arquivos de uma vez só, ela também os organiza por episódio e temporada.
#######################
### bojack horseman ###
#######################
# leitura das legendas dos episodios
bojack <- read.subtitles.serie(dir = "subtitles/bojack_horseman/")
Após a leitura das legendas, precisamos transformá-las em um corpus. Isto é fundamental para que possamos proceder com a limpeza do texto, aplicando nele as seguintes transformações:
- converter todas as letras para sua versão minúscula
- remover sinais de pontuação
- remover números
- remover stopwords (palavras vazias de sentido, como: e, para, de e similares)
- remover espaços em branco
# limpeza do texto
bojack_corpus <- tmCorpus(bojack)
bojack_corpus <- tm_map(bojack_corpus, content_transformer(tolower))
bojack_corpus <- tm_map(bojack_corpus, removePunctuation)
bojack_corpus <- tm_map(bojack_corpus, removeNumbers)
bojack_corpus <- tm_map(bojack_corpus, removeWords, stopwords("portuguese"))
bojack_corpus <- tm_map(bojack_corpus, stripWhitespace)
bojack_corpus <- TermDocumentMatrix(bojack_corpus)
bojack_corpus_matrix <- as.matrix(bojack_corpus)
Em seguida, é preciso proceder com a lematização do texto. É necessário identificar e converter formas flexionadas das palavras para as suas versões dicionarizadas. Por exemplo, é preciso tomar as palavras comi, comemos. comeríamos, comia e transformá-las todas em comer.
Não encontrei nenhum pacote que fizesse uma lematização aceitável em português. Assim, tive que implementar a minha própria, baseado no dicionário de lematização encontrado neste link. Ela ficou um pouco lenta de ser aplicada, mas foi a melhor solução que encontrei na minha pesquisa.
# lemmatizacao
lemma_dic <- read.delim(file = "lemmatization/lemmatization-pt.txt", header = FALSE, stringsAsFactors = FALSE)
names(lemma_dic) <- c("stem", "term")
# palavras do bojack que estao no dicionario
palavras <- row.names(bojack_corpus_matrix)
for (j in 1:length(palavras)){
comparacao <- palavras[j] == lemma_dic$term
if (sum(comparacao) == 1){
palavras[j] <- as.character(lemma_dic$stem[comparacao])
} else {
palavras[j] <- palavras[j]
}
}
palavras_bojack <- palavras
bojack_corpus_df <- as.data.frame(bojack_corpus_matrix)
row.names(bojack_corpus_df) <- NULL
bojack_corpus_df$palavras <- palavras_bojack
Após a lematização, é preciso contar as ocorrências de cada palavra e preparar os conjuntos de dados para que sejam plotados:
# agrupar os resultados
bojack_corpus_df <- bojack_corpus_df %>%
group_by(palavras) %>%
summarise_all(sum)
temporadas <- rep(1:5, each = 12)
bojack_corpus_df_col <- t(apply(bojack_corpus_df[, 2:61], 1, function(x) tapply(x, temporadas, sum)))
colnames(bojack_corpus_df_col) <- paste("S0", 1:5, sep = "")
bojack_corpus_df_col <- data.frame(palavra = bojack_corpus_df$palavras,
bojack_corpus_df_col)
bojack_corpus_melt <- melt(bojack_corpus_df_col)
names(bojack_corpus_melt) <- c("palavra", "temporada", "ocorrencias")
# funcao para plotar os graficos de barra
plot.seriado <- function(dados, season, cor = 0){
grafico <- dados %>%
filter(temporada == season) %>%
top_n(n = 10, wt = ocorrencias) %>%
arrange(desc(ocorrencias)) %>%
ggplot(., aes(x = reorder(palavra, ocorrencias), y = ocorrencias, fill = temporada)) +
geom_col(show.legend = FALSE) +
labs(x = "", y = "", title = season) +
coord_flip() +
scale_fill_viridis_d(begin = cor)
return(grafico)
}
No fim, o que obtemos é o seguinte gráfico:
s01 <- plot.seriado(bojack_corpus_melt, "S01", 0.00)
s02 <- plot.seriado(bojack_corpus_melt, "S02", 0.25)
s03 <- plot.seriado(bojack_corpus_melt, "S03", 0.50)
s04 <- plot.seriado(bojack_corpus_melt, "S04", 0.75)
s05 <- plot.seriado(bojack_corpus_melt, "S05", 1.00)
grid.arrange(s01, s02, s03, s04, s05, left = "Palavras", bottom = "Número de Ocorrências")
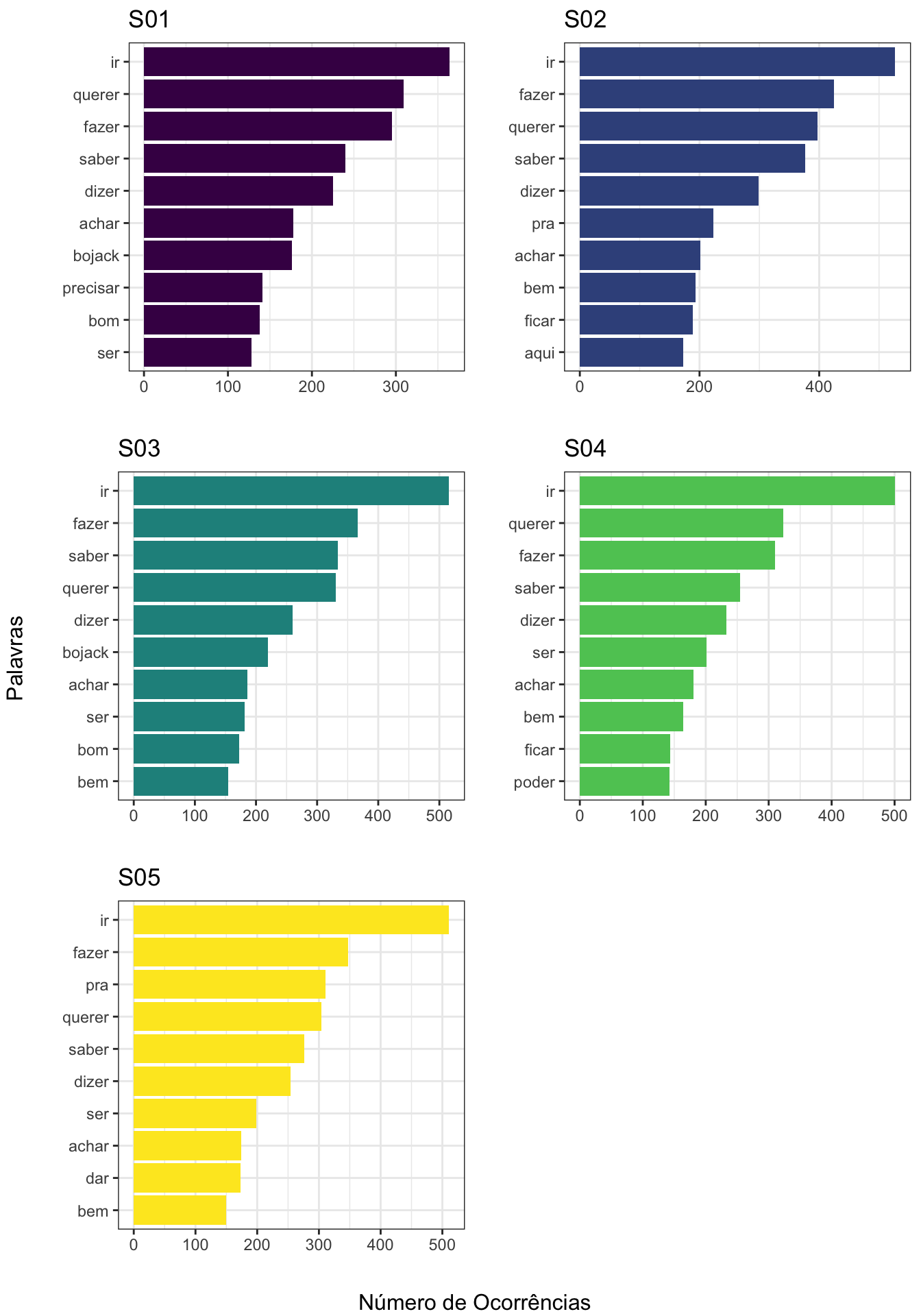
Note que o verbo ir é o que mais aparece em todas as temporadas de Bojack Horseman, com querer e fazer alternando a segunda posição.
A preparação dos dados para a análise dos diálogos de Brooklyn Nine-Nine é análoga à realizada para Bojack Horseman.
###################
### brooklyn 99 ###
###################
# leitura das legendas dos episodios
brooklyn99 <- read.subtitles.serie(dir = "subtitles/brooklyn99/")
# limpeza do texto
brooklyn99_corpus <- tmCorpus(brooklyn99)
brooklyn99_corpus <- tm_map(brooklyn99_corpus, content_transformer(tolower))
brooklyn99_corpus <- tm_map(brooklyn99_corpus, removePunctuation)
brooklyn99_corpus <- tm_map(brooklyn99_corpus, removeNumbers)
brooklyn99_corpus <- tm_map(brooklyn99_corpus, removeWords, stopwords("portuguese"))
brooklyn99_corpus <- tm_map(brooklyn99_corpus, stripWhitespace)
brooklyn99_corpus <- TermDocumentMatrix(brooklyn99_corpus)
brooklyn99_corpus_matrix <- as.matrix(brooklyn99_corpus)
# lemmatizacao
lemma_dic <- read.delim(file = "lemmatization/lemmatization-pt.txt", header = FALSE, stringsAsFactors = FALSE)
names(lemma_dic) <- c("stem", "term")
# palavras do brooklyn99 que estao no dicionario
palavras <- row.names(brooklyn99_corpus_matrix)
for (j in 1:length(palavras)){
comparacao <- palavras[j] == lemma_dic$term
if (sum(comparacao) == 1){
palavras[j] <- as.character(lemma_dic$stem[comparacao])
} else {
palavras[j] <- palavras[j]
}
}
palavras_brooklyn99 <- palavras
brooklyn99_corpus_df <- as.data.frame(brooklyn99_corpus_matrix)
row.names(brooklyn99_corpus_df) <- NULL
brooklyn99_corpus_df$palavras <- palavras_brooklyn99
# agrupar os resultados
brooklyn99_corpus_df <- brooklyn99_corpus_df %>%
group_by(palavras) %>%
summarise_all(sum)
temporadas <- c(rep(1, 22),
rep(2, 23),
rep(3, 23),
rep(4, 22),
rep(5, 22))
brooklyn99_corpus_df_col <- t(apply(brooklyn99_corpus_df[, 2:113], 1, function(x) tapply(x, temporadas, sum)))
colnames(brooklyn99_corpus_df_col) <- paste("S0", 1:5, sep = "")
brooklyn99_corpus_df_col <- data.frame(palavra = brooklyn99_corpus_df$palavras,
brooklyn99_corpus_df_col)
brooklyn99_corpus_melt <- melt(brooklyn99_corpus_df_col)
names(brooklyn99_corpus_melt) <- c("palavra", "temporada", "ocorrencias")
# funcao para plotar os graficos de barra
plot.seriado <- function(dados, season, cor = 0){
grafico <- dados %>%
filter(temporada == season) %>%
top_n(n = 10, wt = ocorrencias) %>%
arrange(desc(ocorrencias)) %>%
ggplot(., aes(x = reorder(palavra, ocorrencias), y = ocorrencias, fill = temporada)) +
geom_col(show.legend = FALSE) +
labs(x = "", y = "", title = season) +
coord_flip() +
scale_fill_viridis_d(begin = cor)
return(grafico)
}
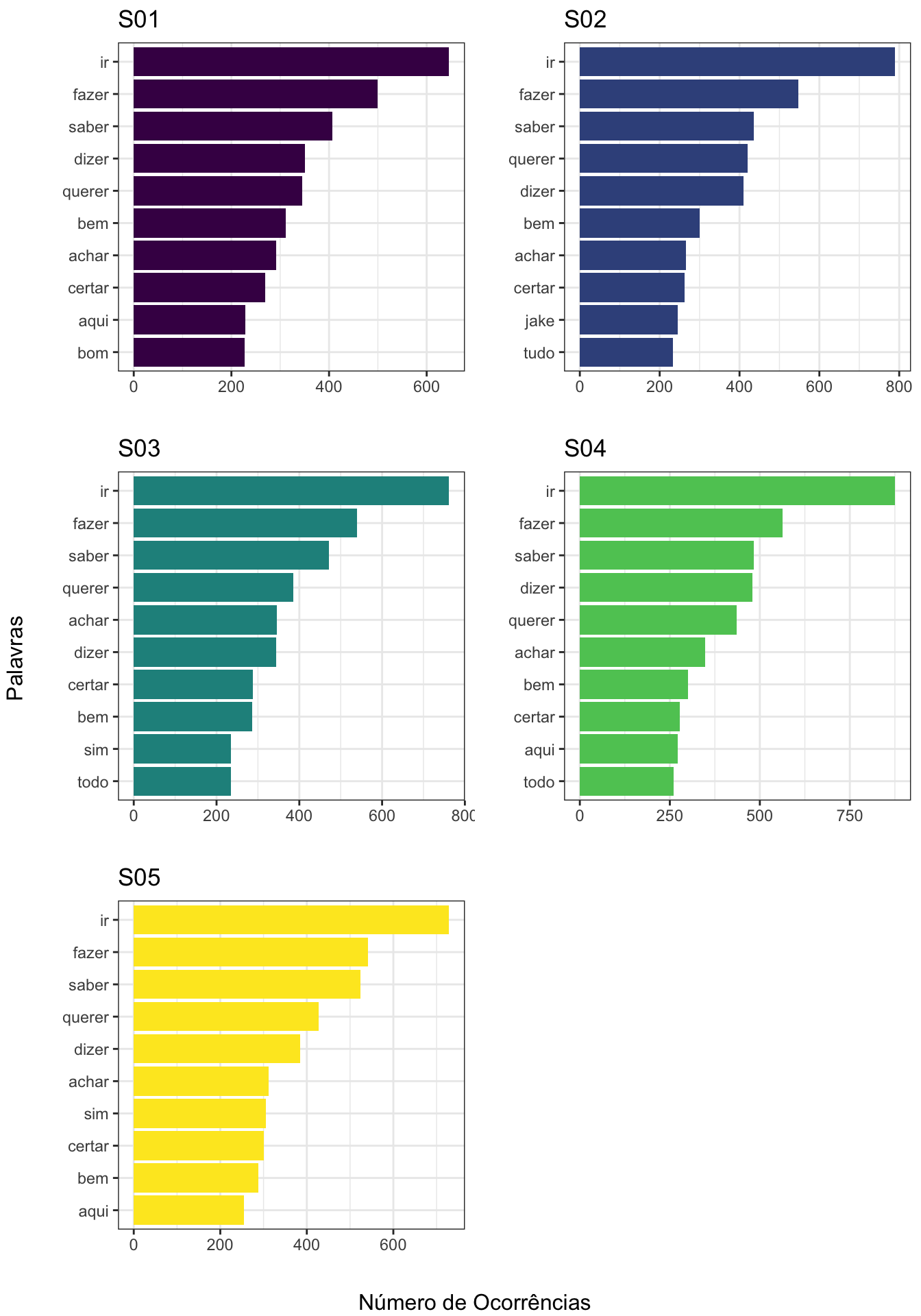
E ao fazer a contagem das palavras que mais aparecem e colocá-las em um gráfico, eis que o resultado é praticamente idêntico ao de Bojack Horseman:
s01 <- plot.seriado(brooklyn99_corpus_melt, "S01", 0.00)
s02 <- plot.seriado(brooklyn99_corpus_melt, "S02", 0.25)
s03 <- plot.seriado(brooklyn99_corpus_melt, "S03", 0.50)
s04 <- plot.seriado(brooklyn99_corpus_melt, "S04", 0.75)
s05 <- plot.seriado(brooklyn99_corpus_melt, "S05", 1.00)
grid.arrange(s01, s02, s03, s04, s05, left = "Palavras", bottom = "Número de Ocorrências")
sentimentos <- read.table(file = "sentiment/sentiword.txt", sep = "\t", header = TRUE)
sentimentos <- sentimentos %>%
group_by(Termo) %>%
summarise(positivo = max(PosScore), negativo = max(NegScore)) %>%
mutate(Termo = trimws(Termo, which = "left"))
pos <- sentimentos[, c(1, 2)]
neg <- sentimentos[, c(1, 3)]
# sentimento para cada episodio
bojack_sentimento_positivo <- 0
bojack_sentimento_negativo <- 0
for (j in 1:(dim(bojack_corpus_df)[2]-1)){
# palavras do j-esimo episodio
a <- bojack_corpus_matrix[, j]
a <- data.frame(Termo = names(a),
Ocorrencias = a)
row.names(a) <- NULL
# juntando sentimentos com as palavras do episodio - caso positivo
x <- left_join(a, pos, by = "Termo") %>%
na.omit()
sentimento_positivo <- sum(x$Ocorrencias*x$positivo)/sum(a$Ocorrencias)
# juntando sentimentos com as palavras do episodio - caso negativo
x <- left_join(a, neg, by = "Termo") %>%
na.omit()
sentimento_negativo <- sum(x$Ocorrencias*x$negativo)/sum(a$Ocorrencias)
bojack_sentimento_positivo[j] <- sentimento_positivo
bojack_sentimento_negativo[j] <- sentimento_negativo
}
bojack_plot <- data.frame(episodio = 1:length(bojack_sentimento_positivo),
temporada = factor(temporadas),
positivo = bojack_sentimento_positivo,
negativo = bojack_sentimento_negativo)
# sentimento para cada episodio
brooklyn99_sentimento_positivo <- 0
brooklyn99_sentimento_negativo <- 0
for (j in 1:(dim(brooklyn99_corpus_df)[2]-1)){
# palavras do j-esimo episodio
a <- brooklyn99_corpus_matrix[, j]
a <- data.frame(Termo = names(a),
Ocorrencias = a)
row.names(a) <- NULL
# juntando sentimentos com as palavras do episodio - caso positivo
x <- left_join(a, pos, by = "Termo") %>%
na.omit()
sentimento_positivo <- sum(x$Ocorrencias*x$positivo)/sum(a$Ocorrencias)
# juntando sentimentos com as palavras do episodio - caso negativo
x <- left_join(a, neg, by = "Termo") %>%
na.omit()
sentimento_negativo <- sum(x$Ocorrencias*x$negativo)/sum(a$Ocorrencias)
brooklyn99_sentimento_positivo[j] <- sentimento_positivo
brooklyn99_sentimento_negativo[j] <- sentimento_negativo
}
brooklyn99_plot <- data.frame(episodio = 1:length(brooklyn99_sentimento_positivo),
temporada = factor(temporadas),
positivo = brooklyn99_sentimento_positivo,
negativo = brooklyn99_sentimento_negativo)
Análise de Sentimentos Link para o cabeçalho
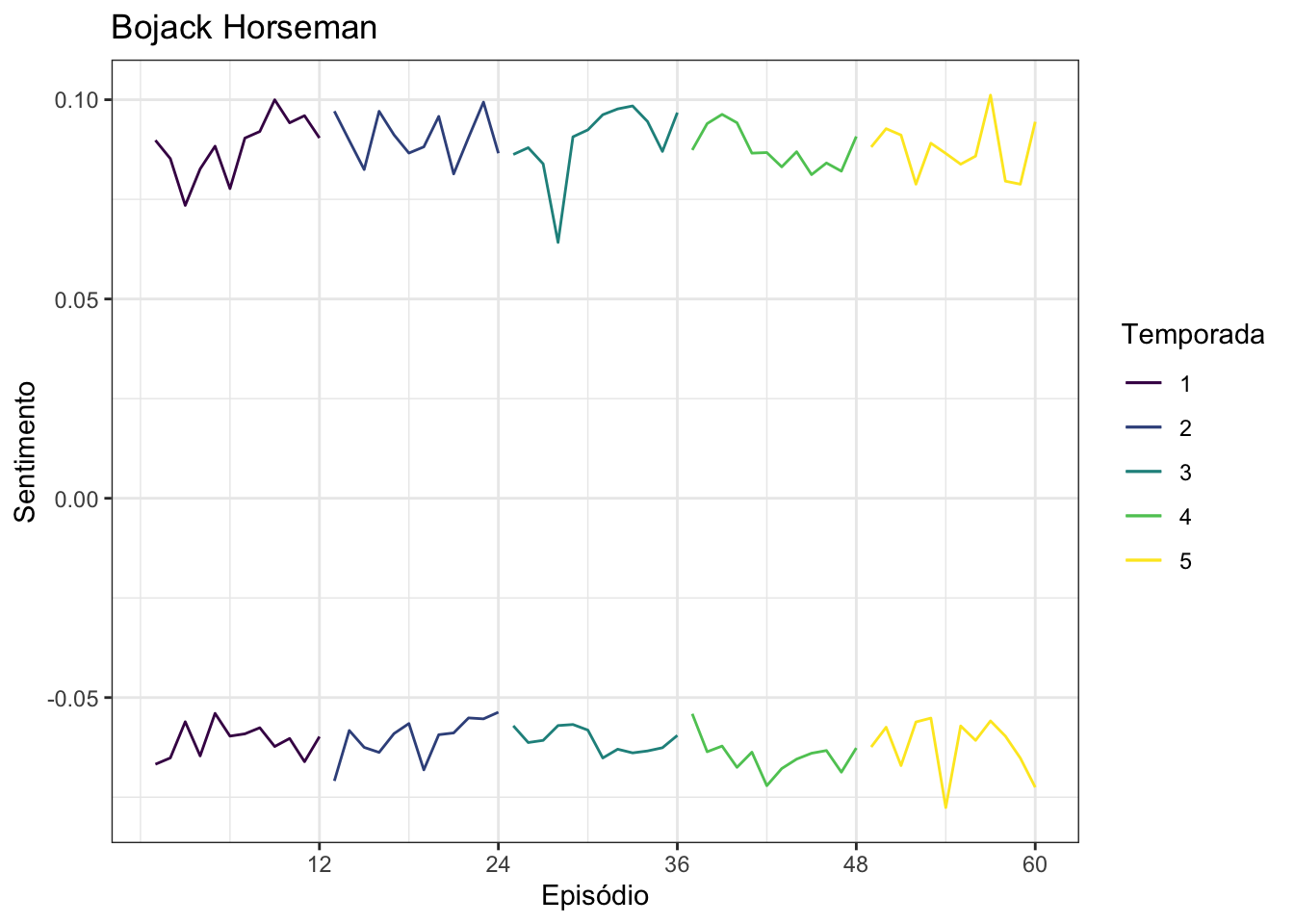
É possível atribuir pesos positivos e negativos a palavras, em uma escala de 0 a 1. Por exemplo, a palavra incapaz pode ter valor 0.75 positivo, enquanto a palavra hiperventilar tem peso negativo de 0.5. Ao atribuir estes pesos para as palavras ditas no seriado, é possível verificar como, em uma escala de 0 a 1 para valores positivos e de -1 a 0 para valores negativos, como estão os diálogos das séries. O dicionário SentiWordNet-PT-BR , criado pelo Pedro Thales, me ajudou muito nesta tarefa. Os resultados obtidos estão nas figuras abaixo.
ggplot(bojack_plot, aes(x = episodio, colour = temporada)) +
geom_line(aes(y = positivo)) +
geom_line(aes(y = -negativo)) +
scale_x_continuous(breaks = seq(12, 60, 12)) +
labs(x = "Episódio", y = "Sentimento", colour = "Temporada", title = "Bojack Horseman") +
scale_colour_viridis_d()
ggplot(brooklyn99_plot, aes(x = episodio, colour = temporada)) +
geom_line(aes(y = positivo)) +
geom_line(aes(y = -negativo)) +
scale_x_continuous(breaks = c(22, 45, 68, 90, 112)) +
labs(x = "Episódio", y = "Sentimento", colour = "Temporada", title = "Brooklyn 99") +
scale_colour_viridis_d()
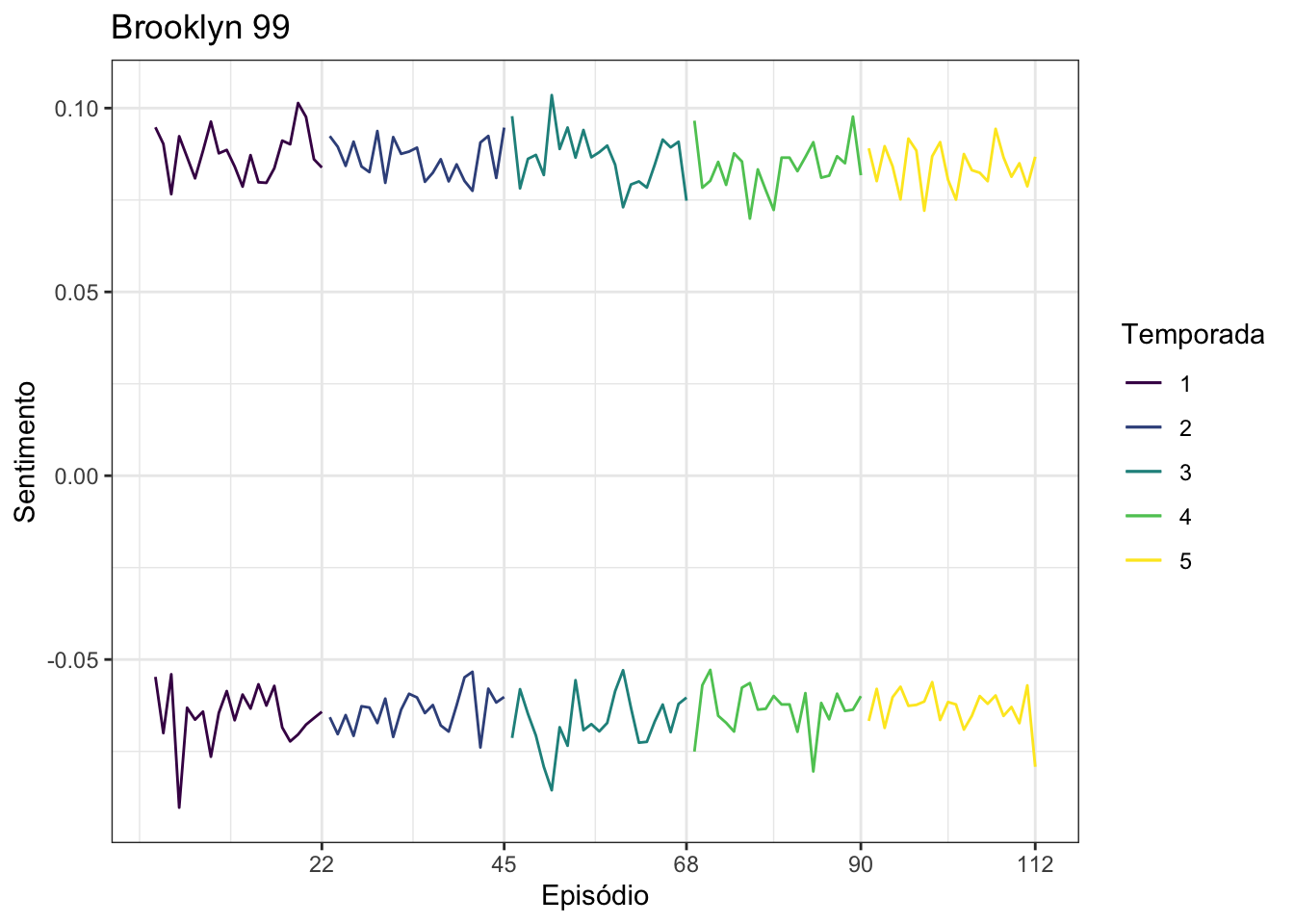
Novamente, parece não haver muita diferença de uma série para outra.
Conclusão Link para o cabeçalho
Reconheço que este não é o resultado que eu esperava. Eu imaginava que as palavras com maior frequência para Bojack Horseman teriam conotação negativa, enquanto em Brooklyn Nine-Nine elas teriam mais conotação positiva. Pelo visto, me enganei.
Caberia fazer uma segunda análise nestes dados, talvez com os diálogos originais. Afinal, como as traduções que usei não são, pode ser que elas estejam influenciando no resultado final da análise. Além disso, é possível que meus dicionários de lematização e sentimentos possuam problemas, fazendo com que os resultados não sejam exatamente aqueles que ocorrem na língua original dos seriados.
De toda forma, foi uma análise divertida de fazer. Tentarei repeti-la co fututo, mas aí com corpus originais do português.
Os arquivos utilizados nesta análise estão neste repositório do GitHub.