Pensei em criar uma visualização que comparasse o resultado dos alunos de escola pública e privada no ENEM. Para isso, comparei o desempenho de cada tipo de escola nas provas do ENEM, verificando se existe correlação entre as notas. Entretanto, juntei um mapa de calor a isso, para procurar clusters nos quais houvesse maior concentração de candidatos. O primeiro caso que analisei foram as notas em Matemática e Ciências Humanas.
library(tidyverse)
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.0 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
theme_set(theme_bw())
library(gridExtra)
##
## Attaching package: 'gridExtra'
##
## The following object is masked from 'package:dplyr':
##
## combine
load("dados/enem2021.RData")
limite_x <- scale_x_continuous(limits = c(0, 1000))
limite_y <- scale_y_continuous(limits = c(0, 1000))
opcao_viridis <- "E"
g1 <-
enem2021_limpo |>
filter(TP_ESCOLA == "Pública") |>
ggplot(aes(x = NU_NOTA_CH, y = NU_NOTA_MT)) +
geom_hex() +
scale_fill_viridis_c(option = opcao_viridis) +
labs(x = "", y = "", fill = "Contagem", title = "Pública") +
limite_x +
limite_y
g2 <-
enem2021_limpo |>
filter(TP_ESCOLA == "Privada") |>
ggplot(aes(x = NU_NOTA_CH, y = NU_NOTA_MT)) +
geom_hex() +
scale_fill_viridis_c(option = opcao_viridis) +
labs(x = "", y = "", fill = "Contagem", title = "Privada") +
limite_x +
limite_y
grid.arrange(g1, g2, nrow = 1,
left = "Nota em Matemática",
bottom = "Nota em Ciências Humanas")
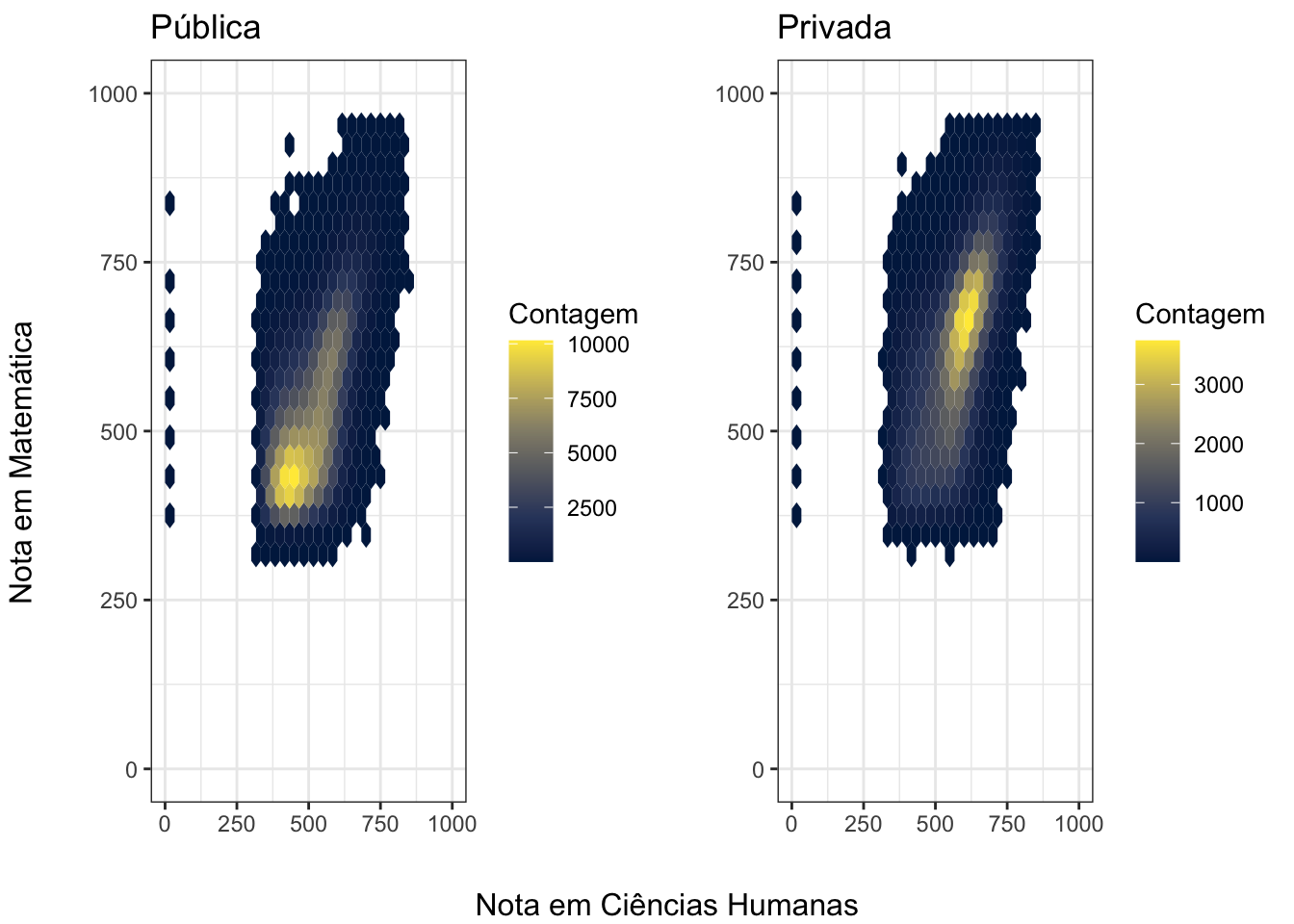
É interessante notar como há uma correlação positiva entre as notas, como era de se esperar, para ambos os tipos de escola. Entretanto, a concentração de alunos de escola pública é maior próximo dos 470 e 500 pontos para Ciências Humanas e Matemática, respectivamente, enquanto para as escolas privadas esses valores sobem para 580 e 620, mais de 100 pontos de diferença.
Quando olhamos para o tipos de dependência administrativa, obtemos resultados interessantes:
g1 <-
enem2021_limpo |>
filter(TP_DEPENDENCIA_ADM_ESC == "Federal") |>
ggplot(aes(x = NU_NOTA_CH, y = NU_NOTA_MT)) +
geom_hex() +
scale_fill_viridis_c(option = opcao_viridis) +
labs(x = "", y = "", fill = "Contagem", title = "Federal") +
limite_x +
limite_y
g2 <-
enem2021_limpo |>
filter(TP_DEPENDENCIA_ADM_ESC == "Estadual") |>
ggplot(aes(x = NU_NOTA_CH, y = NU_NOTA_MT)) +
geom_hex() +
scale_fill_viridis_c(option = opcao_viridis) +
labs(x = "", y = "", fill = "Contagem", title = "Estadual") +
limite_x +
limite_y
g3 <-
enem2021_limpo |>
filter(TP_DEPENDENCIA_ADM_ESC == "Municipal") |>
ggplot(aes(x = NU_NOTA_CH, y = NU_NOTA_MT)) +
geom_hex() +
scale_fill_viridis_c(option = opcao_viridis) +
labs(x = "", y = "", fill = "Contagem", title = "Municipal") +
limite_x +
limite_y
g4 <-
enem2021_limpo |>
filter(TP_DEPENDENCIA_ADM_ESC == "Privada") |>
ggplot(aes(x = NU_NOTA_CH, y = NU_NOTA_MT)) +
geom_hex() +
scale_fill_viridis_c(option = opcao_viridis) +
labs(x = "", y = "", fill = "Contagem", title = "Privada") +
limite_x +
limite_y
grid.arrange(g1, g2, g3, g4, nrow = 2,
left = "Nota em Matemática",
bottom = "Nota em Ciências Humanas")
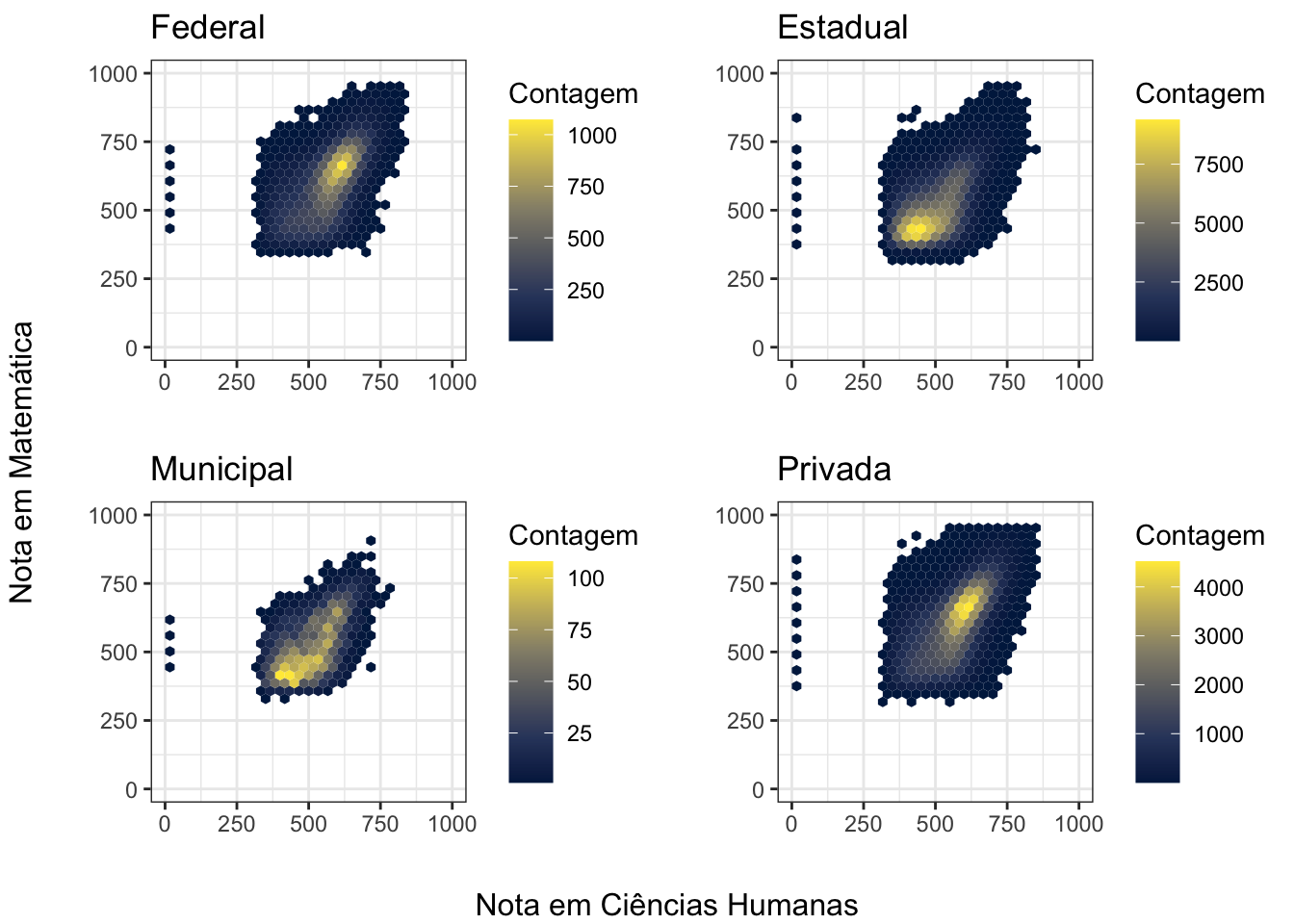
Note como as concentrações de notas para escolas federais e privadas estão muito próximas, enquanto as notas para as escolcas estaduais e municipais apresentam uma grande defasagem.
Fica como exercício para o leitor verificar se esse tipo de comportamento se mantém para as notas das outras provas. O conjunto de dados completo do ENEM pode ser obtido no site do INEP. Entretanto, o conjunto de dados enem_limpo, utilizado nessa análise e bem mais leve, pode ser baixado neste link.