ÇINAR, KOKLU e TAŞDEMİR (2020) propuseram classificar, através de imagens, dois tipos de uvas-passas cultivadas na Tuquia chamadas Kecimen e Besni. Para isso, utilizaram três diferentes tipos de algoritmos de aprendizagem de máquina: Regreessão Logística (LR), Perceptron Multicamadas (MLP) e Máquina de Vetor Suporte (SVM). Alguns dos resultados obtidos pelos autores em seu conjunto de treinamento estão reportados na Tabela abaixo:
| Métrica | LR | MLP | SVM |
|---|---|---|---|
| Acurácia | 85.22 | 86.33 | 86.44 |
| Sensitividade | 84.09 | 84.57 | 84.17 |
| Especificidade | 86.44 | 88.29 | 89.05 |
| Fonte: Tabela 6 de ÇINAR, KOKLU e TAŞDEMİR (2020). |
O objetivo desse post é verificar se é possível melhorar os resultados da análise publicada no artigo. Os dados completos utilizados na pesquisa podem ser encontrados no Kaggle. São 900 observações de 450 exemplares de cada tipo de passa. As medidas reportadas foram obtidas automaticamente, a partir de fotografias digitais analisadas por computador. As variáveis disponíveis são as seguintes:
Area: número de pixels dentro dos limites da passaPerimeter: distância entre os limites do grão de passas e os pixels ao seu redorMajorAxisLength: comprimento do eixo principal, que é a reta mais longa que pode ser desenhada no grão de passasMinorAxisLength: comprimento do eixo secundário, que é a reta mais curta que pode ser desenhada no grão de passasEccentricity: excentricidade da elipse teórica com os mesmos eixos das passasConvexArea: número de pixels da menor superfície convexa da região formada pelo grão de passasExtent: razão entre a região formada pelo grão de passa para o total de pixels na caixa delimitadoraClass: tipo de passa (Kecimen ou Besni)
Utilizando essas informações, pretendo criar um modelo preditivo para esse conjunto de dados e compará-lo aos resultados do artigo. Com sorte, talvez melhorar o resultado obtido pelos autores. Maiores detalhes a respeito dos conceitos utilizados nessa modelagem podem ser encontrados em meu site introbigdata.org, com o conteúdo completo da disciplina de aprendizagem de máquinha que ministro na UFRN.
Meu primeiro passo será utilizar um algoritmo diferente dos autores para atacar o problema. Minha escolha é pelo Random Forest, um algoritmo poderoso e que me é bastante conhecido. Isso posto, vou começar a análise lendo os dados e fazendo uma análise exploratória básica.
Análise Exploratória dos Dados Link para o cabeçalho
Aqui, verifico a relação entre as variáveis preditoras, bem como a distribuição dos daods:
# pacotes necessarios
library(readxl)
library(tidymodels)
## ── Attaching packages ────────────────────────────────────── tidymodels 1.1.1 ──
## ✔ broom 1.0.5 ✔ recipes 1.0.10
## ✔ dials 1.2.1 ✔ rsample 1.2.0
## ✔ dplyr 1.1.4 ✔ tibble 3.2.1
## ✔ ggplot2 3.5.0 ✔ tidyr 1.3.1
## ✔ infer 1.0.6 ✔ tune 1.1.2
## ✔ modeldata 1.3.0 ✔ workflows 1.1.4
## ✔ parsnip 1.2.0 ✔ workflowsets 1.0.1
## ✔ purrr 1.0.2 ✔ yardstick 1.3.0
## ── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
## ✖ purrr::accumulate() masks foreach::accumulate()
## ✖ purrr::discard() masks scales::discard()
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::group_rows() masks kableExtra::group_rows()
## ✖ dplyr::lag() masks stats::lag()
## ✖ recipes::step() masks stats::step()
## ✖ purrr::when() masks foreach::when()
## • Learn how to get started at https://www.tidymodels.org/start/
theme_set(theme_bw())
# leitura dos dados
passas <- read_excel(path = "dados/Raisin_Dataset.xlsx") |>
mutate(Class = factor(Class))
# definir semente aleatoria
set.seed(1788)
# 70% dos dados como treino
passas_split <- initial_split(passas, prop = .7, strata = Class)
# criar os conjuntos de dados de treino e teste
passas_treino <- training(passas_split)
passas_teste <- testing(passas_split)
library(GGally)
## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2
passas_treino |>
select(-Class) |>
ggpairs()
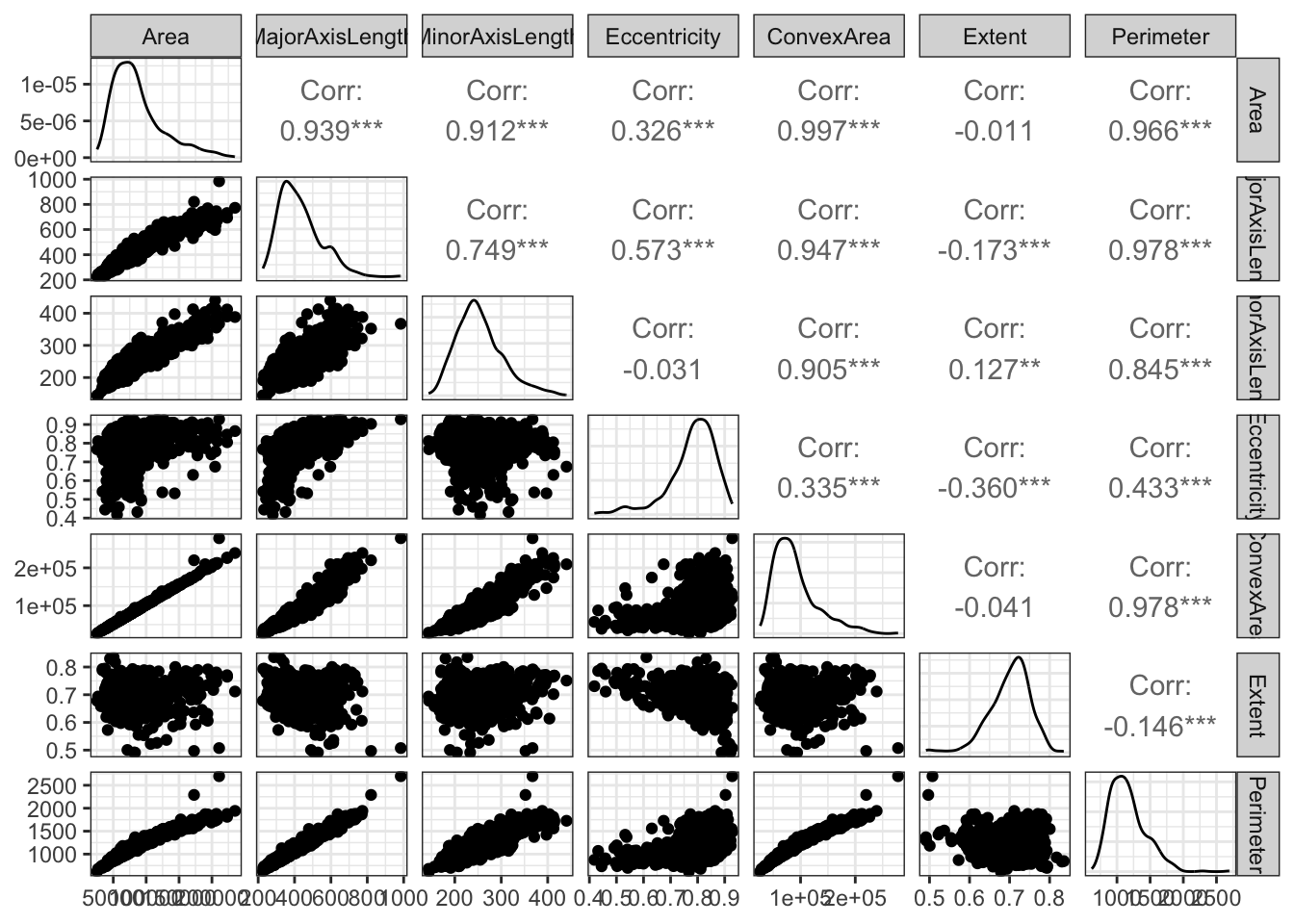
É possível perceber que há pares de variáveis com correlações muito altas, como MajorAxisLength, MinorAxisLength, ConvexArea e Perimeter com Area, todas acima de 0.9. No total, são 8 pares de variáveis com valor de correlação linear acima de 0.9.
Além disso, as variáveis Area, MajorAxisLength, MinorAxisLength, ConvexArea e Perimeter apresentam assimetria à direita, enquanto as variáveis Eccentricity e Extent apresentam assimetria à esquerda. Não há variáveis com distribuição simétrica. Isso não será um problema para o Random Forest, pois ele é capaz de lidar tranquilamente com dados assimétricos.
O passo seguinte é criar uma receita para o pré-processamento dos dados. Nesse caso, vou apenas deixar a variável resposta com o memso número de observações para cada classe com a função step_downsample e, em seguida, deixar todas as minhas variáveis preditoras com média zero (step_center) e desvio padrão 1 (step_scale).
# receita
passas_rec <-
recipe(Class ~ .,
data = passas_treino) |>
# remover observacoes de modo que todos os niveis de Class
# fiquem com o mesmo numero de observacoes
themis::step_downsample(Class) |>
# center/scale
step_center(-Class) |>
step_scale(-Class)
Boxplots são outra forma de verificar se há algo interessante nos dados:
prep(passas_rec) |>
juice() |>
pivot_longer(-Class) |>
ggplot(aes(fill = Class)) +
geom_boxplot(aes(y = value), colour = "grey50") +
facet_wrap(~ name, scales = "free") +
labs(x = "", y = "Valor", fill = "Class") +
scale_fill_viridis_d() +
scale_y_continuous(labels = comma_format())
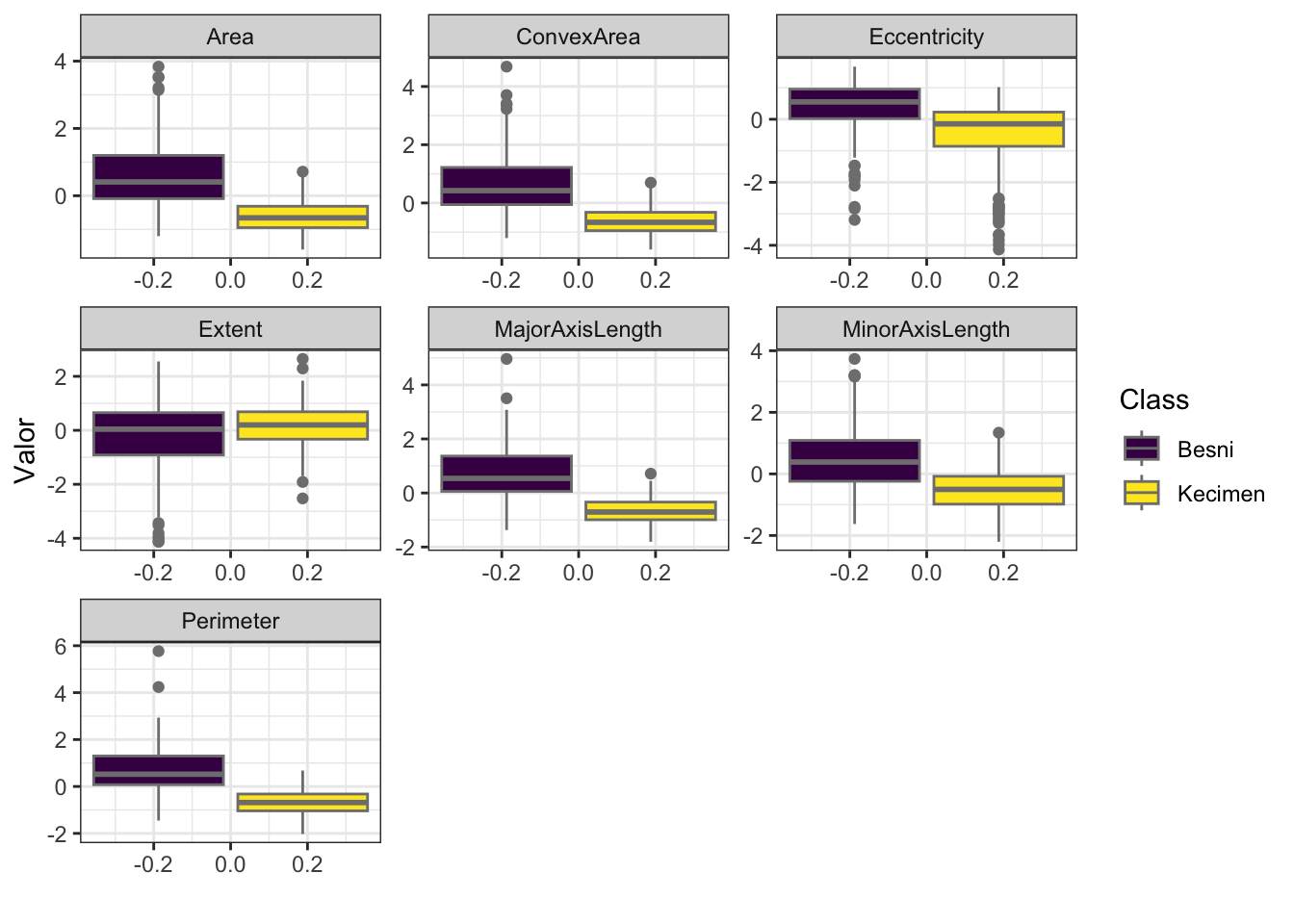
Com exceção de Extent, todas as outras variáveis apresentam uma boa diferença entre os níveis das classes de passas, sugerindo que podem ser boas preditoras para a variável resposta.
Como o que nos interessa é classificar as passas, uma análise de componentes principais é um boa ferramenta de visualização dos dados:
library(ggfortify)
## Registered S3 method overwritten by 'ggfortify':
## method from
## autoplot.glmnet parsnip
passas_treino_pca <-
prep(passas_rec) |>
juice() |>
select(-Class) |>
prcomp()
summary(passas_treino_pca)
## Importance of components:
## PC1 PC2 PC3 PC4 PC5 PC6 PC7
## Standard deviation 2.2011 1.1995 0.79924 0.21800 0.14987 0.08006 0.03034
## Proportion of Variance 0.6921 0.2056 0.09126 0.00679 0.00321 0.00092 0.00013
## Cumulative Proportion 0.6921 0.8977 0.98895 0.99574 0.99895 0.99987 1.00000
autoplot(passas_treino_pca, data = passas_treino, colour = "Class") +
scale_colour_viridis_d()
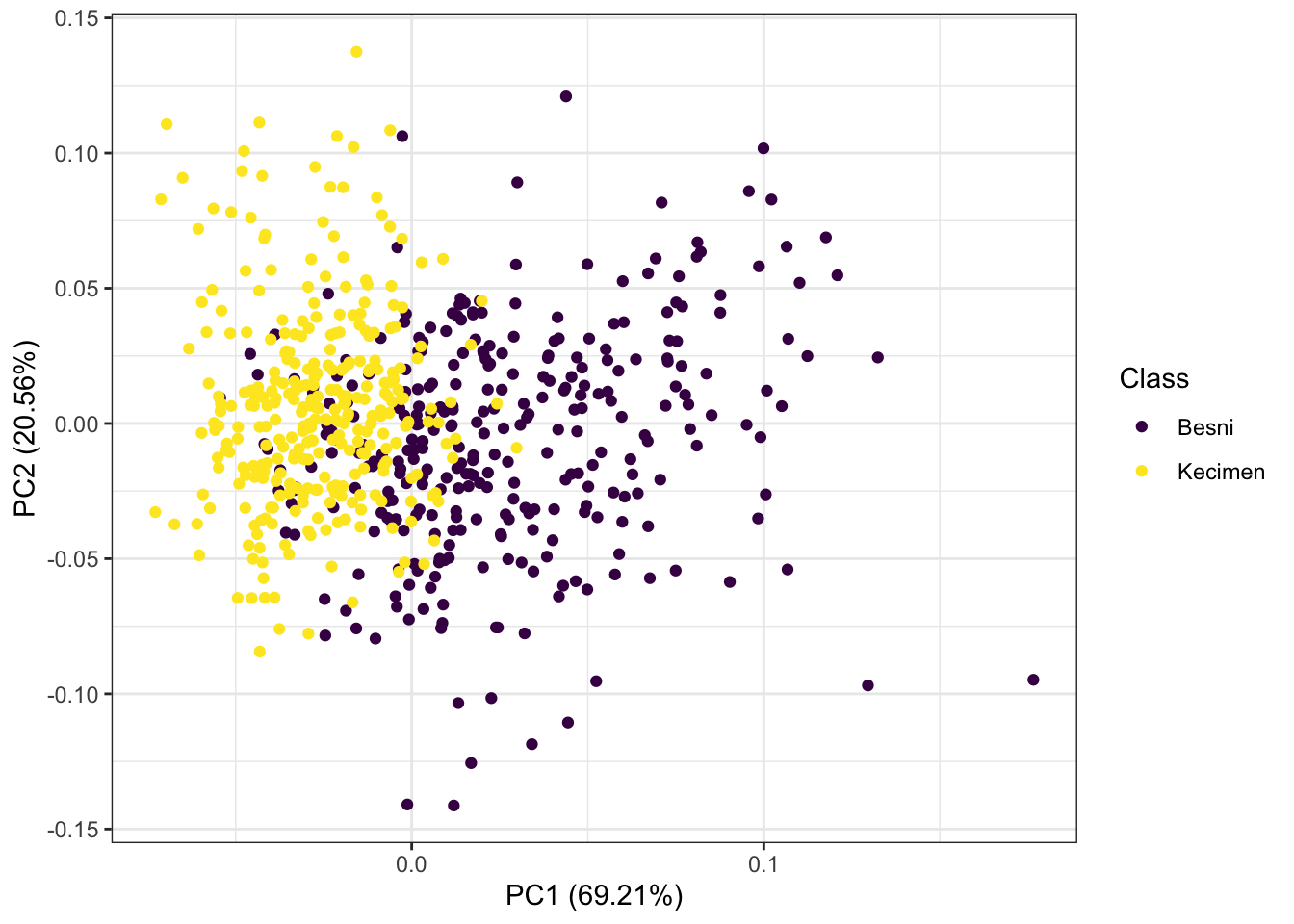
É possível perceber uma sobreposição muito grande entre as classes Besni e Kecimen no centro do gráfico da PCA. Essa característica dos dados nos sugere que eles não são linearmente separáveis. Além disso, o fato de 89,77% da variância dos dados ser explicada pelas duas primeiras componentes principais nos dá mais segurança para fazer essa afirmação.
Agora é possível proceder com a modelagem em si.
Modelagem com Random Forest Link para o cabeçalho
Como os conjuntos de treino e teste já foram preparados, o próximo passo é separar os dados de modo a realizar a validação cruzada. Estou usando 7 folds para esse problema.
set.seed(3887)
passas_treino_cv <- vfold_cv(passas_treino, v = 7)
Em seguida, defino a grade de procura dos melhores hiperparâmetros. No total, testarei 135 modelos diferentes.
# definicao do tuning
passas_rf_tune <-
rand_forest(
mtry = tune(),
trees = tune(),
min_n = tune()
) %>%
set_mode("classification") %>%
set_engine("ranger", importance = "impurity")
# grid de procura
passas_rf_grid <-
grid_regular(mtry(range(1, 7)),
trees(range(1000, 2000)),
min_n(range(10, 50)),
levels = c(9, 3, 5))
passas_rf_grid
## # A tibble: 105 × 3
## mtry trees min_n
## <int> <int> <int>
## 1 1 1000 10
## 2 2 1000 10
## 3 3 1000 10
## 4 4 1000 10
## 5 5 1000 10
## 6 6 1000 10
## 7 7 1000 10
## 8 1 1500 10
## 9 2 1500 10
## 10 3 1500 10
## # ℹ 95 more rows
Agora é o momento de criar meu workflow para, em seguida, analisar o resultado do modelo ajustado:
# criar workflow
passas_wflow <-
workflow() |>
add_recipe(passas_rec) |>
add_model(passas_rf_tune)
# avaliacao do modelo
passas_rf_fit_tune <-
passas_wflow |>
tune_grid(
resamples = passas_treino_cv,
grid = passas_rf_grid
)
Com as métricas estimadas, vou explorar os resultados obtidos, de modo a saber se alguma das minhas escolhas de hiperparâmetros maximizou a acurácia do meu modelo. No momento, não estou preocupado com a área sob a curva, pois o artigo original de onde tirei esses dados não usa essa métrica.
# explorando os resultados
passas_rf_fit_tune |>
collect_metrics() |>
filter(.metric == "accuracy") |>
mutate(trees = factor(trees)) |>
ggplot(aes(x = mtry, y = mean, colour = trees, group = trees)) +
geom_line() +
geom_point() +
facet_wrap(~ min_n, ncol = 1) +
scale_x_continuous(breaks = seq(1, 7, 1)) +
scale_colour_viridis_d() +
theme_bw()
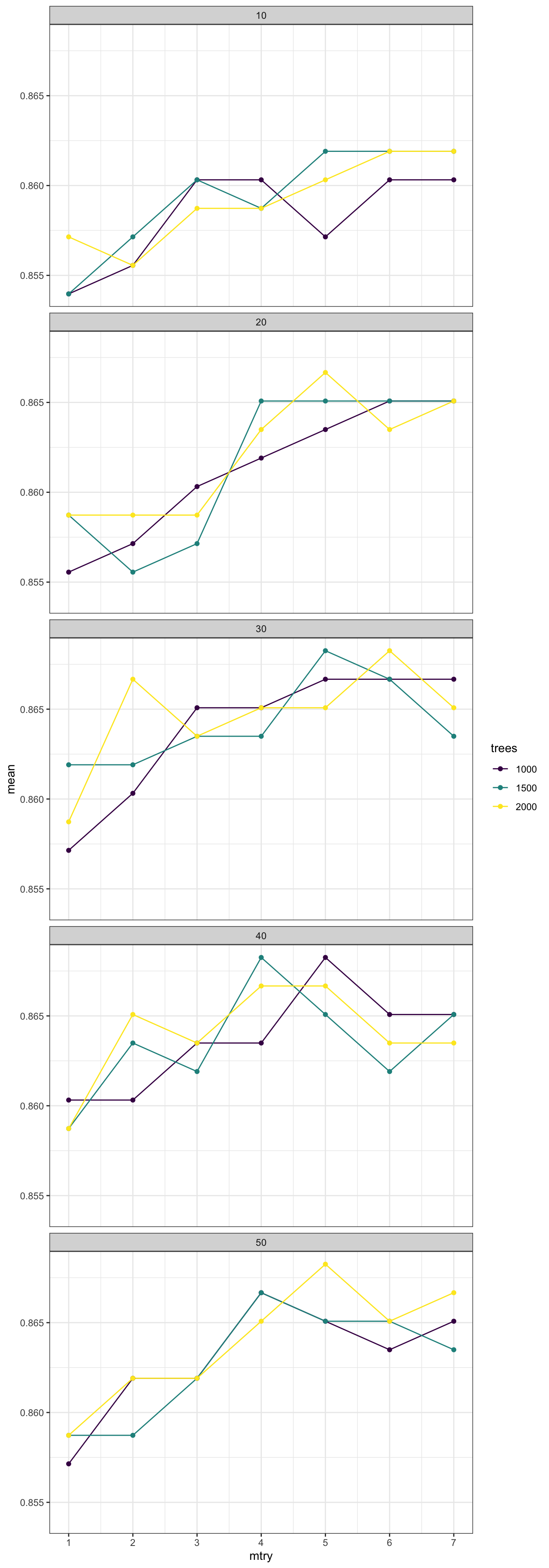
É possível perceber com esses gráficos que o máximo global da acurácia foi atingido nesse intervalo de hiperparâmetros escolhido.
Mas qual foi o melhor modelo de todos? Abaixo podemos conferir isso de acordo com a acurácia:
passas_rf_fit_tune |>
show_best("accuracy", 1)
## # A tibble: 1 × 9
## mtry trees min_n .metric .estimator mean n std_err .config
## <int> <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 5 1500 30 accuracy binary 0.868 7 0.0187 Preprocessor1_Model…
Portanto, o melhor modelo para esses dados, de modo que o resultado seja comparável ao trabalho que vem sendo feito, é o modelo com maior acurácia. Esse modelo possui
- mtry 5 (variáveis selecionadas aleatoriamente para construir as árvores)
- trees 1500 (quantidade de árvores usadas)
- min_n 30 (número mínimo de elementos no nó final de cada árvore da floresta)
Agora é necessário ajustar o melhor modelo aos nossos dados e finalizar o workflow.
# melhor modelo
passas_rf_best <-
passas_rf_fit_tune |>
select_best("accuracy")
passas_rf_final <-
passas_wflow |>
finalize_workflow(passas_rf_best)
passas_rf_final <- fit(passas_rf_final, passas_treino)
passas_rf_final
## ══ Workflow [trained] ══════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: rand_forest()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 3 Recipe Steps
##
## • step_downsample()
## • step_center()
## • step_scale()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Ranger result
##
## Call:
## ranger::ranger(x = maybe_data_frame(x), y = y, mtry = min_cols(~5L, x), num.trees = ~1500L, min.node.size = min_rows(~30L, x), importance = ~"impurity", num.threads = 1, verbose = FALSE, seed = sample.int(10^5, 1), probability = TRUE)
##
## Type: Probability estimation
## Number of trees: 1500
## Sample size: 630
## Number of independent variables: 7
## Mtry: 5
## Target node size: 30
## Variable importance mode: impurity
## Splitrule: gini
## OOB prediction error (Brier s.): 0.1025123
Verificando o resultado no conjunto de teste, vemos que as acurácias são bem próximas, não sugerindo nenhum tipo de sobreajuste aos dados.
# resultados no conjunto de teste
resultado_rf <-
passas_teste |>
bind_cols(predict(passas_rf_final, passas_teste) |>
rename(predicao_rf = .pred_class))
metrics(resultado_rf,
truth = Class,
estimate = predicao_rf,
options = "accuracy")
## # A tibble: 2 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 accuracy binary 0.859
## 2 kap binary 0.719
Por fim, temos as medidas de sensitividade (verdadeiros positivos - detectação de passas Besni) e especificidade (verdadeiros negativos - detecção de passas Kecimen) no conjunto de teste:
# sensitividade
sens(resultado_rf,
truth = Class,
estimate = predicao_rf)
## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 sens binary 0.874
# especificidade
spec(resultado_rf,
truth = Class,
estimate = predicao_rf)
## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 spec binary 0.844
Juntando tudo, isto é, os resultados do paper com nossa modelagem, temos o seguinte:
| Métrica | LR | MLP | SVM | RF |
|---|---|---|---|---|
| Acurácia | 85.2 | 86.3 | 86.4 | 85.9 |
| Sensitividade | 84.0 | 84.6 | 84.2 | 87.4 |
| Especificidade | 86.4 | 88.3 | 89.1 | 84.4 |
| Fonte: Tabela 6 de ÇINAR, KOKLU e TAŞDEMİR (2020). |
Tivemos acurácia e especificidade levemente inferiores, com a sensitividade um pouco maior. Ou seja, nosso modelo não melhorou o resultado do artigo. Entretanto, podemos pensar em alternativas para obter um resultado melhor como, por exemplo, utilizar outro algoritmo de predição. Por isso, na próxima seção, utilizarei o K Vizinhos Mais Próximos para ver que resultados são possíveis de serem obtidos.
Modelagem com K Vizinhos Mais Próximos Link para o cabeçalho
Com o novo algoritmo, o procedimento praticamente o mesmo que utilizamos no Random Forest. A principal diferença ocorre no pré-processamento dos dados. Dessa vez, iremos utilizar a transformação logaritmo para deixar simétricas as variáveis assimétricas à direta e a transformação de Box-Cox para deixar simétricas as variáveis assimétricas à esquerda. De resto, utilizaremos os mesmos conjuntos de treino e teste e a mesma reamostragem para a validação cruzada.
# receita
passas_rec <-
recipe(Class ~ .,
data = passas_treino) |>
# remover observacoes de modo que todos os niveis de Class
# fiquem com o mesmo numero de observacoes
themis::step_downsample(Class) |>
# variaveis assimetricas a direita
step_log(Area,
MajorAxisLength,
MinorAxisLength,
ConvexArea,
Perimeter) |>
# variaveis assimetricas a esquerda
step_BoxCox(Eccentricity,
Extent,
limits = c(-10, 10)) |>
# center/scale
step_center(-Class) |>
step_scale(-Class)
# visualizando o resultado das transformações
prep(passas_rec) |>
juice() |>
select(-Class) |>
ggpairs()
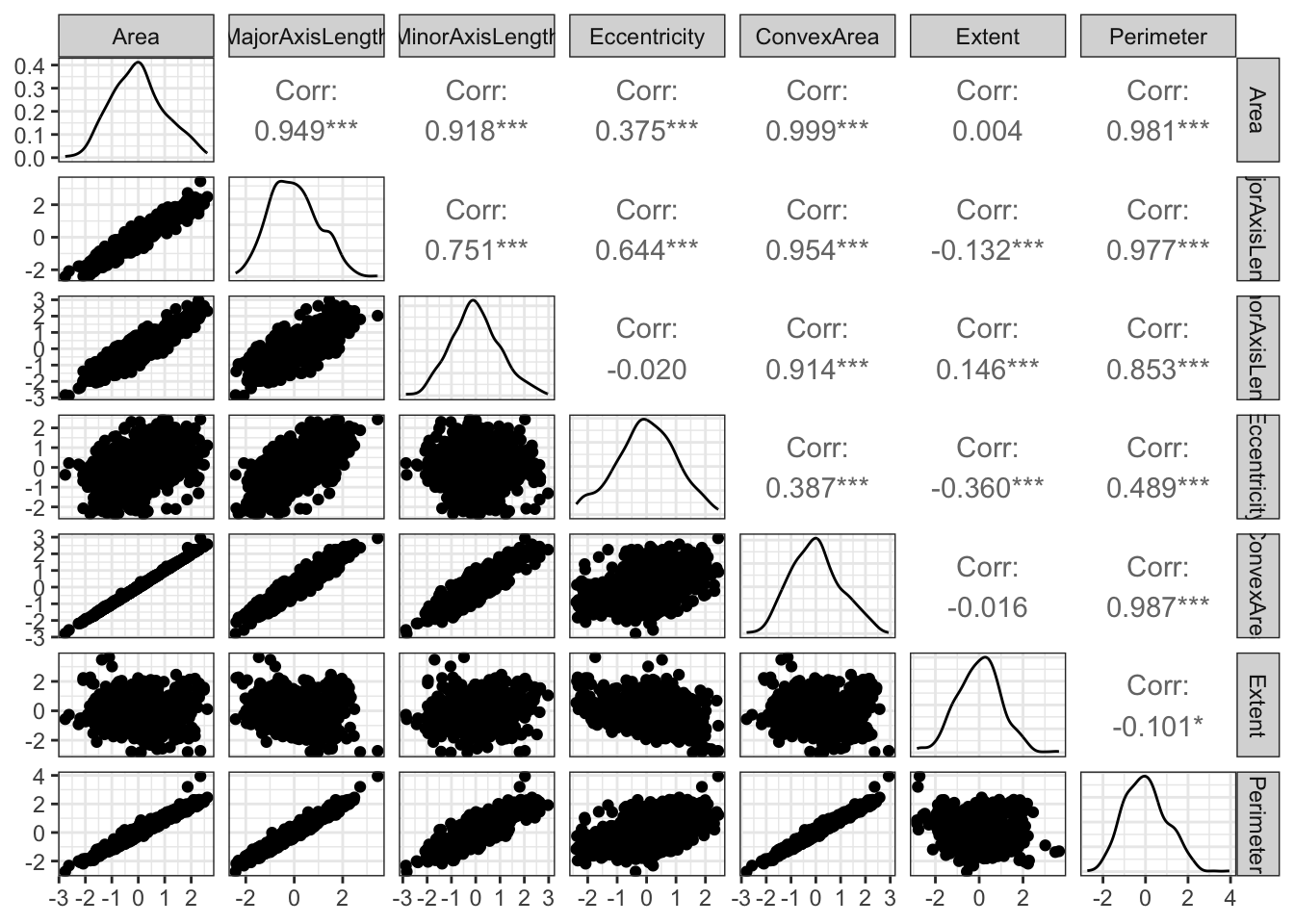
Note como agora todas as variáveis preditoras estão simétricas em relação à média.
Com essas transformações definidas, podemos presseguir com o ajuste do modelo:
# definicao do tuning
passas_knn_tune <-
nearest_neighbor(
neighbors = tune(),
weight_func = tune(),
dist_power = tune()
) |>
set_engine("kknn") |>
set_mode("classification")
# grid de procura
passas_knn_grid <-
grid_regular(neighbors(range = c(3, 51)),
weight_func(c("rectangular", "triangular", "optimal")),
dist_power(),
levels = c(25, 3, 2))
# atualizar workflow
passas_wflow <-
workflow() |>
add_recipe(passas_rec) |>
add_model(passas_knn_tune)
# avaliacao do modelo
passas_knn_fit_tune <-
passas_wflow |>
tune_grid(
resamples = passas_treino_cv,
grid = passas_knn_grid
)
# explorando os resultados
passas_knn_fit_tune |>
collect_metrics() |>
mutate(dist_power = factor(dist_power)) |>
ggplot(aes(x = neighbors, y = mean, color = dist_power)) +
geom_line() +
geom_point() +
facet_grid(weight_func ~ .metric) +
scale_x_continuous(breaks = seq(3, 51, 6)) +
scale_colour_viridis_d() +
theme_bw()
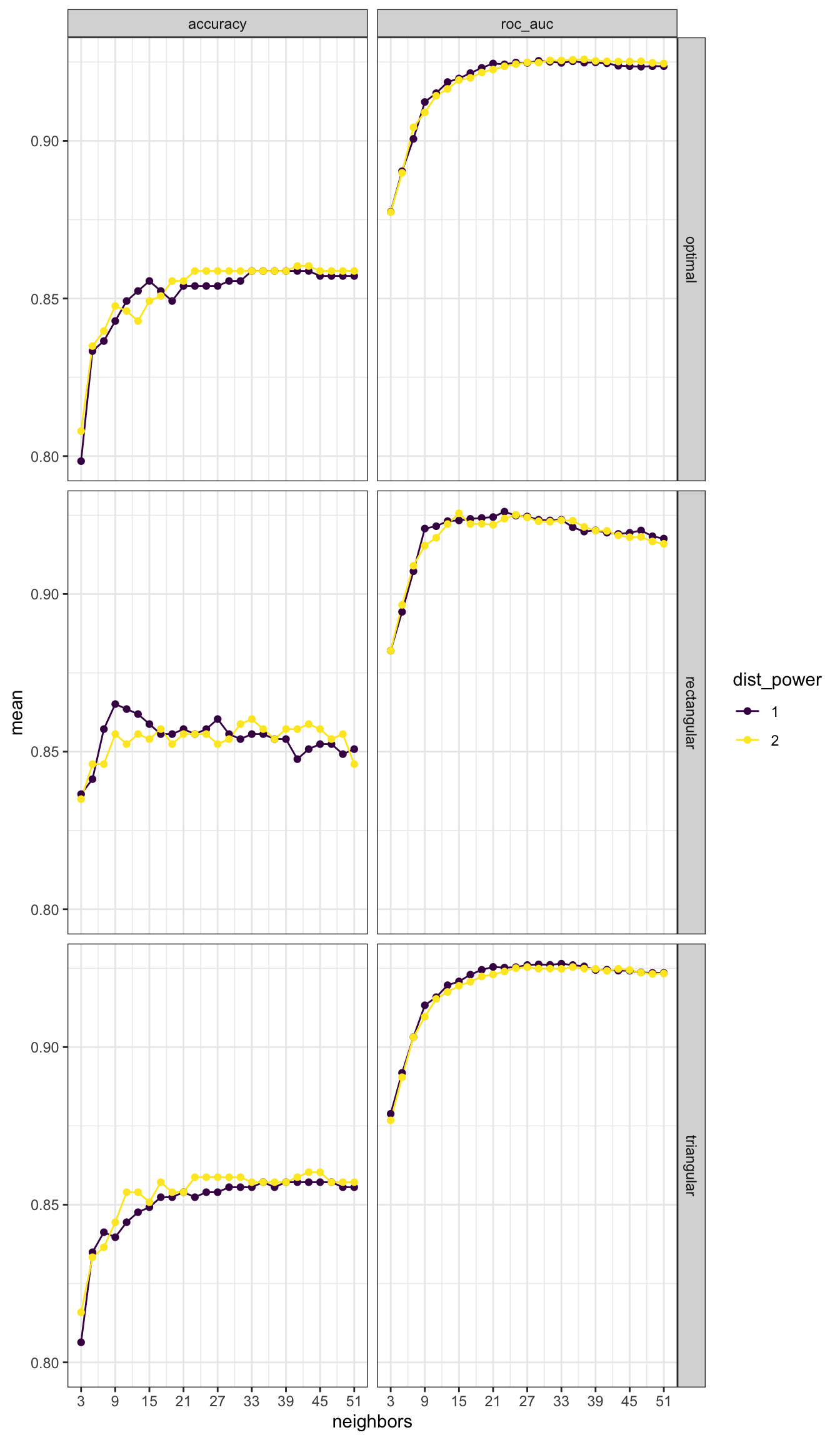
Embora os decaimentos das curvas para a acurácia sejam bastante lentos após o máximo ter sido atingido, é possível perceber que sim, o máximo global foi atingido nesse intervalo de parâmetros escolhido.
# melhor modelo
passas_knn_fit_tune |>
show_best("accuracy", 1)
## # A tibble: 1 × 9
## neighbors weight_func dist_power .metric .estimator mean n std_err
## <int> <chr> <dbl> <chr> <chr> <dbl> <int> <dbl>
## 1 9 rectangular 1 accuracy binary 0.865 7 0.0177
## # ℹ 1 more variable: .config <chr>
Em particular, o melhor modelo para esses dados possui
- 9 vizinhos
- função peso retangular
- distância de Manhattan
# ajuste do melhor modelo
passas_knn_best <-
passas_knn_fit_tune |>
select_best("accuracy")
passas_knn_final <-
passas_wflow |>
finalize_workflow(passas_knn_best)
passas_knn_final <- fit(passas_knn_final, passas_treino)
passas_knn_final
## ══ Workflow [trained] ══════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: nearest_neighbor()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 5 Recipe Steps
##
## • step_downsample()
## • step_log()
## • step_BoxCox()
## • step_center()
## • step_scale()
##
## ── Model ───────────────────────────────────────────────────────────────────────
##
## Call:
## kknn::train.kknn(formula = ..y ~ ., data = data, ks = min_rows(9L, data, 5), distance = ~1, kernel = ~"rectangular")
##
## Type of response variable: nominal
## Minimal misclassification: 0.1428571
## Best kernel: rectangular
## Best k: 9
Com o modelo final ajustado, prosseguimos com o cálculo aas métricas no conjunto de teste:
# resultados no conjunto de teste
resultado_knn <-
passas_teste |>
bind_cols(predict(passas_knn_final, passas_teste) |>
rename(predicao_knn = .pred_class))
metrics(resultado_knn,
truth = Class,
estimate = predicao_knn,
options = "accuracy")
## # A tibble: 2 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 accuracy binary 0.878
## 2 kap binary 0.756
# sensitividade
sens(resultado_knn,
truth = Class,
estimate = predicao_knn)
## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 sens binary 0.881
# especificidade
spec(resultado_knn,
truth = Class,
estimate = predicao_knn)
## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 spec binary 0.874
Não há sinais de sobreajuste e obtivemos bons resultados, tanto para a acurácia, quanto para a sensitividade e especificidade. Compilando todos os modelos, obtemos o seguinte resultado:
| Métrica | LR | MLP | SVM | RF | KNN |
|---|---|---|---|---|---|
| Acurácia | 85.2 | 86.3 | 86.4 | 85.9 | 87.8 |
| Sensitividade | 84.0 | 84.6 | 84.2 | 87.4 | 88.1 |
| Especificidade | 86.4 | 88.3 | 89.1 | 84.4 | 87.4 |
| Fonte: Tabela 6 de ÇINAR, KOKLU e TAŞDEMİR (2020). |
Como é possível ver, o K Vizinhos Mais Próximos obteve o melhor resultado em termos de acurácia e sensitividade (detecção de passas Besni), ficando em terceiro lugar em especificidade (detecção de passas Kecimen).
Conclusão Link para o cabeçalho
Conseguimos, com pouquíssimo esforço, melhorar o resultado do trabalho de ÇINAR, KOKLU e TAŞDEMİR (2020). Foi uma melhora marginal, mas apenas escolhemos um algoritmo que consideramos mais adequado e fizemos um engenharia de variáveis simples.
Acreditamos que é possível melhorar ainda mais esse resultado, se outros algoritmos mais poderosos forem testados, principalmente modelos ensemble. Além disso, uma engenharia de variáveis mais sofisticada poderia, em tese, melhorar ainda mais o desempenho dos algoritmos por nós escolhidos.