Introdução Link para o cabeçalho
Recentemente o site Data Hackers realizou uma pesquisa com pessoas que trabalham com Ciência de Dados. As respostas coletadas pelos questionários foram compilados e disponibilizados no Kaggle. Nesta primeira parte da minha análise irei fazer uma série de análises descritivas, a fim de ter uma noção de como estão algumas características deste mercado.
Preparação dos Dados Link para o cabeçalho
Como em qualquer análise de dados, o primeiro passo é importá-los para o R.
# pacotes necessarios
library(tidyverse)
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.2.0 ✔ readr 2.1.6
## ✔ forcats 1.0.1 ✔ stringr 1.6.0
## ✔ ggplot2 4.0.2 ✔ tibble 3.3.1
## ✔ lubridate 1.9.5 ✔ tidyr 1.3.2
## ✔ purrr 1.2.1
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
theme_set(theme_bw())
# leitura dos dados
survey <- read_csv("data/datahackers-survey-2019-anonymous-responses.csv") %>%
janitor::clean_names()
## Rows: 1765 Columns: 170
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (19): ('P0', 'id'), ('P2', 'gender'), ('P5', 'living_state'), ('P8', 'd...
## dbl (151): ('P1', 'age'), ('P3', 'living_in_brasil'), ('P6', 'born_or_gradua...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
A seguir, processo a coluna p5_living_state, mantendo apenas a sigla do estado em que o respondente mora. Além disso, há dados faltantes para o estado de quem mora no exterior. Portanto, então vou colocar o nível “Exterior” para essas pessoas.
# manter apenas as siglas para os estados e
# completar os NA de p5_living_state com Exterior
survey <- survey %>%
mutate(p5_living_state = gsub("[\\(\\)]", "", regmatches(p5_living_state, gregexpr("\\(.*?\\)", p5_living_state)))) %>%
mutate(p5_living_state = ifelse(p5_living_state == "character0", "Exterior", p5_living_state))
A seguir, crio um ordenamento que faça sentido para a variável p16_salary_range:
# criar ordenamento para p16_salary_range
survey <- survey %>%
mutate(p16_salary_range = fct_explicit_na(p16_salary_range, na_level = "Não Informado")) %>%
mutate(p16_salary_range =
factor(p16_salary_range,
levels = c("Não Informado",
"Menos de R$ 1.000/mês",
"de R$ 1.001/mês a R$ 2.000/mês",
"de R$ 2.001/mês a R$ 3000/mês",
"de R$ 3.001/mês a R$ 4.000/mês",
"de R$ 4.001/mês a R$ 6.000/mês",
"de R$ 6.001/mês a R$ 8.000/mês",
"de R$ 8.001/mês a R$ 12.000/mês",
"de R$ 12.001/mês a R$ 16.000/mês",
"de R$ 16.001/mês a R$ 20.000/mês",
"de R$ 20.001/mês a R$ 25.000/mês",
"Acima de R$ 25.001/mês")))
## Warning: There was 1 warning in `mutate()`.
## ℹ In argument: `p16_salary_range = fct_explicit_na(p16_salary_range, na_level =
## "Não Informado")`.
## Caused by warning:
## ! `fct_explicit_na()` was deprecated in forcats 1.0.0.
## ℹ Please use `fct_na_value_to_level()` instead.
De modo análogo, segue uma ordenação para a variável p8_degree_level:
# criar ordenamento para p8_degree_level
survey <- survey %>%
mutate(p8_degreee_level = factor(p8_degreee_level,
levels = c("Prefiro não informar",
"Não tenho graduação formal",
"Estudante de Graduação",
"Graduação/Bacharelado",
"Pós-graduação",
"Mestrado",
"Doutorado ou Phd")))
A partir de agora inicio a análise dos dados coletados. Como a amostragem não foi feita de maneira probabilística, não há a garantia de que os resultados reportados a seguir sejam extrapoláveis para um grupo de pessoas que não tenha respondido o questionário.
Análise Exploratória Link para o cabeçalho
Como podemos ver no gráfico abaixo, esse é um campo de atuação majoritariamente masculino:
survey %>%
mutate(p2_gender = fct_explicit_na(p2_gender, "Não Informado")) %>%
group_by(p2_gender) %>%
count() %>%
ggplot(aes(x = p2_gender, y = n)) +
geom_col() +
labs(x = "Gênero", y = "Quantidade", title = "Gênero dos Cientistas de Dados Brasileiros")
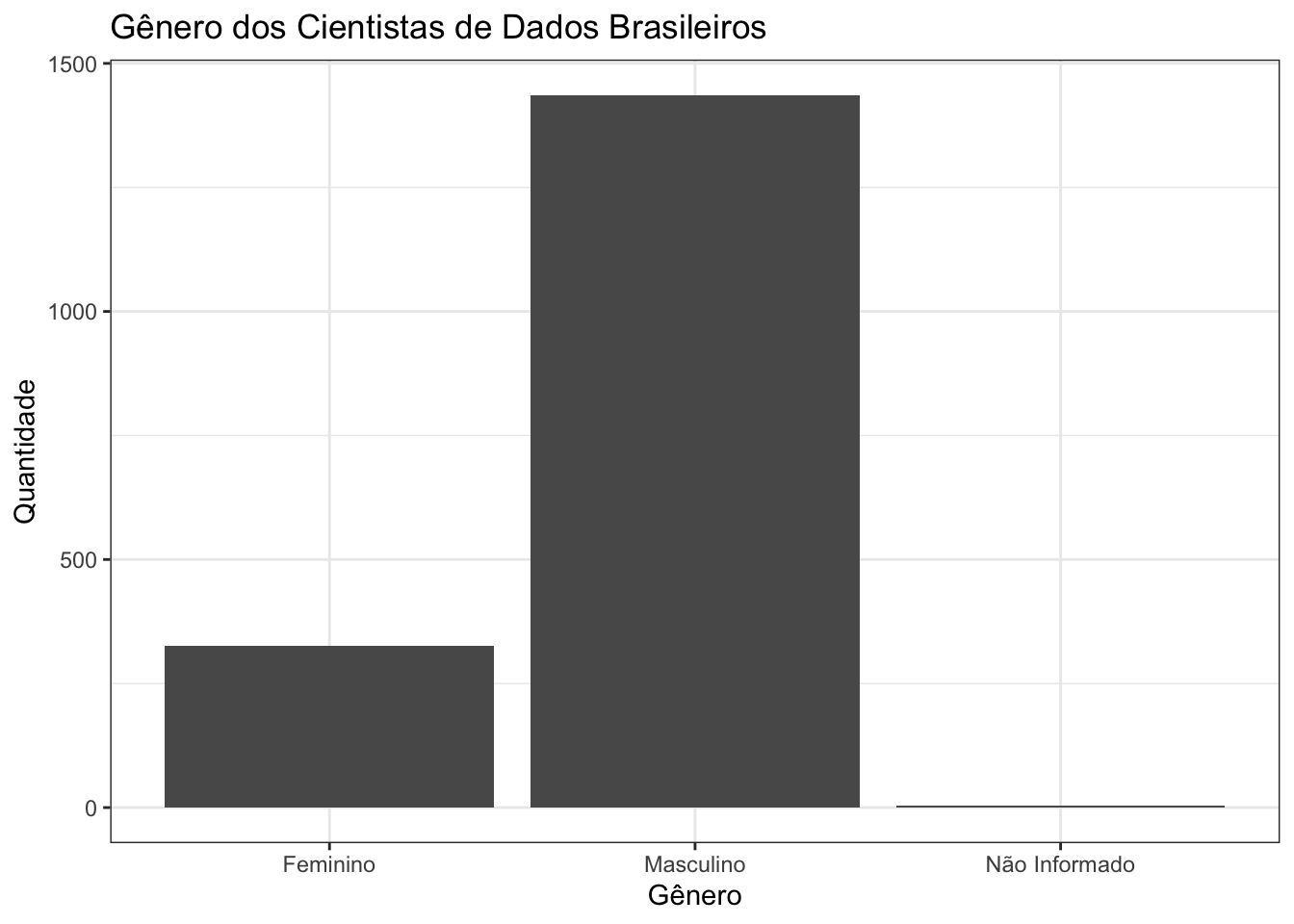
Além disso, nessa amostra não houve respondentes que trabalhassem no Brasil e fora das regiões Sul ou Sudeste:
survey %>%
group_by(p5_living_state) %>%
count() %>%
ggplot(aes(x = reorder(p5_living_state, -n), y = n)) +
geom_col() +
labs(x = "Estado de Residência", y = "Quantidade", title = "Número de Cientistas de Dados por Estado")
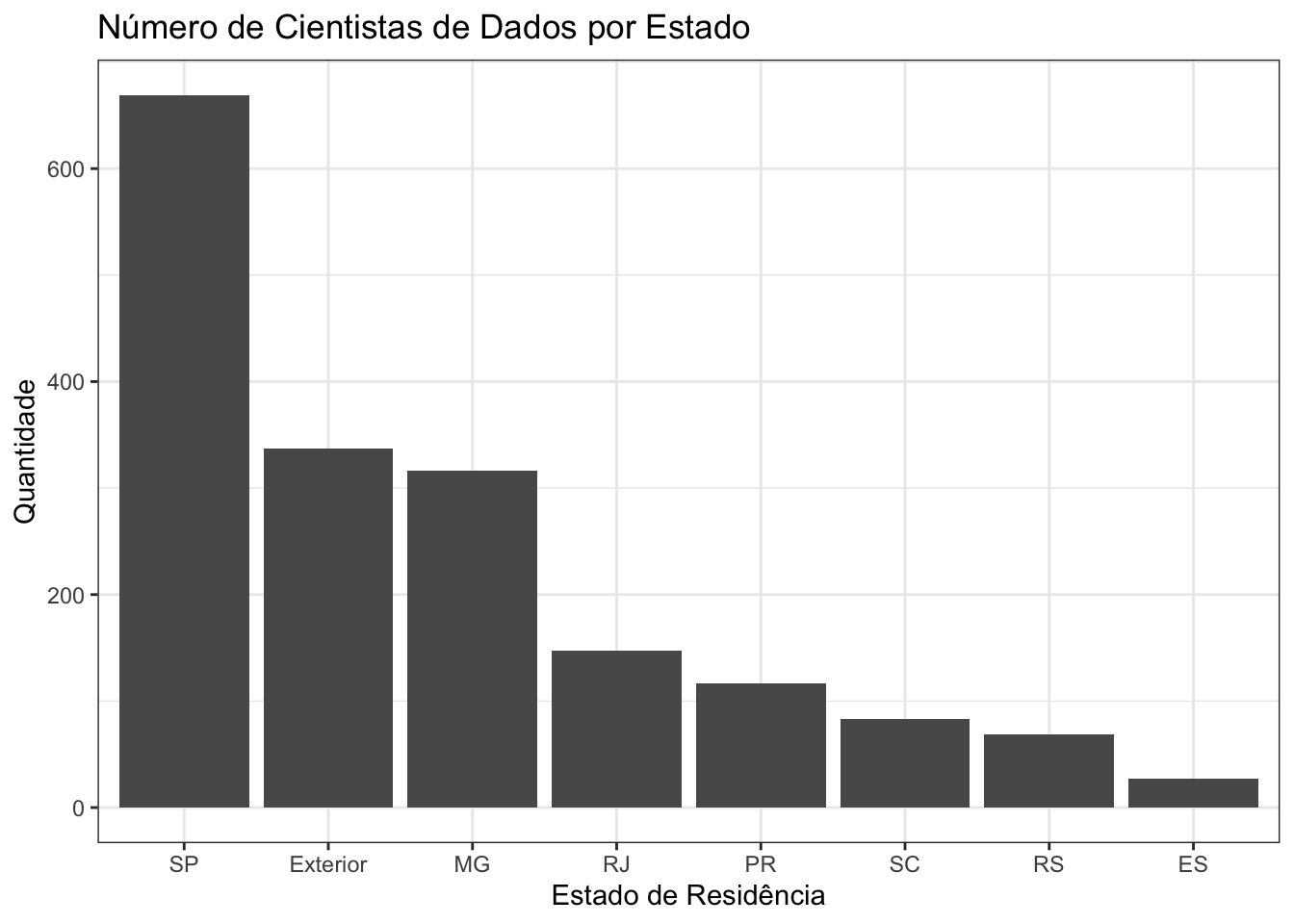
A faixa salarial mais comum é entre R$ 4.001 e R$ 6.000 por mês:
survey %>%
filter(p5_living_state != "Exterior") %>%
group_by(p16_salary_range) %>%
count() %>%
na.omit() %>%
ggplot(aes(x = p16_salary_range, y = n)) +
geom_col() +
labs(x = "Faixa Salarial", y = "Quantidade", title = "Faixa Salarial dos Cientistas de Dados Brasileiros") +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
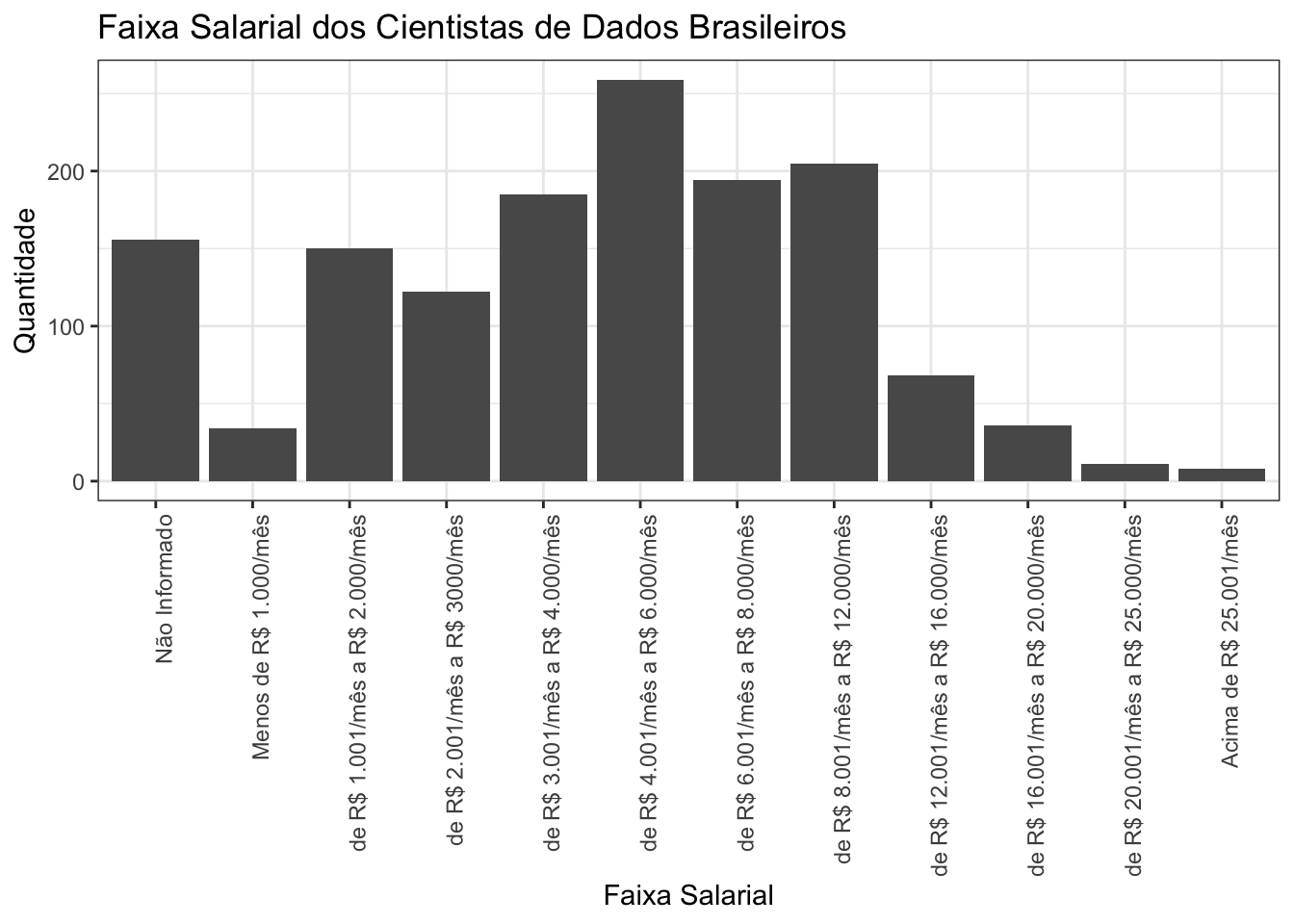
São Paulo possui mais gente recebendo melhores salários:
survey %>%
group_by(p5_living_state, p16_salary_range) %>%
count() %>%
ggplot(aes(x = p16_salary_range, y = p5_living_state, fill = n)) +
geom_tile() +
labs(x = "Faixa Salarial", y = "Estado de Residência", fill = "Qtde") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
scale_fill_viridis_c()
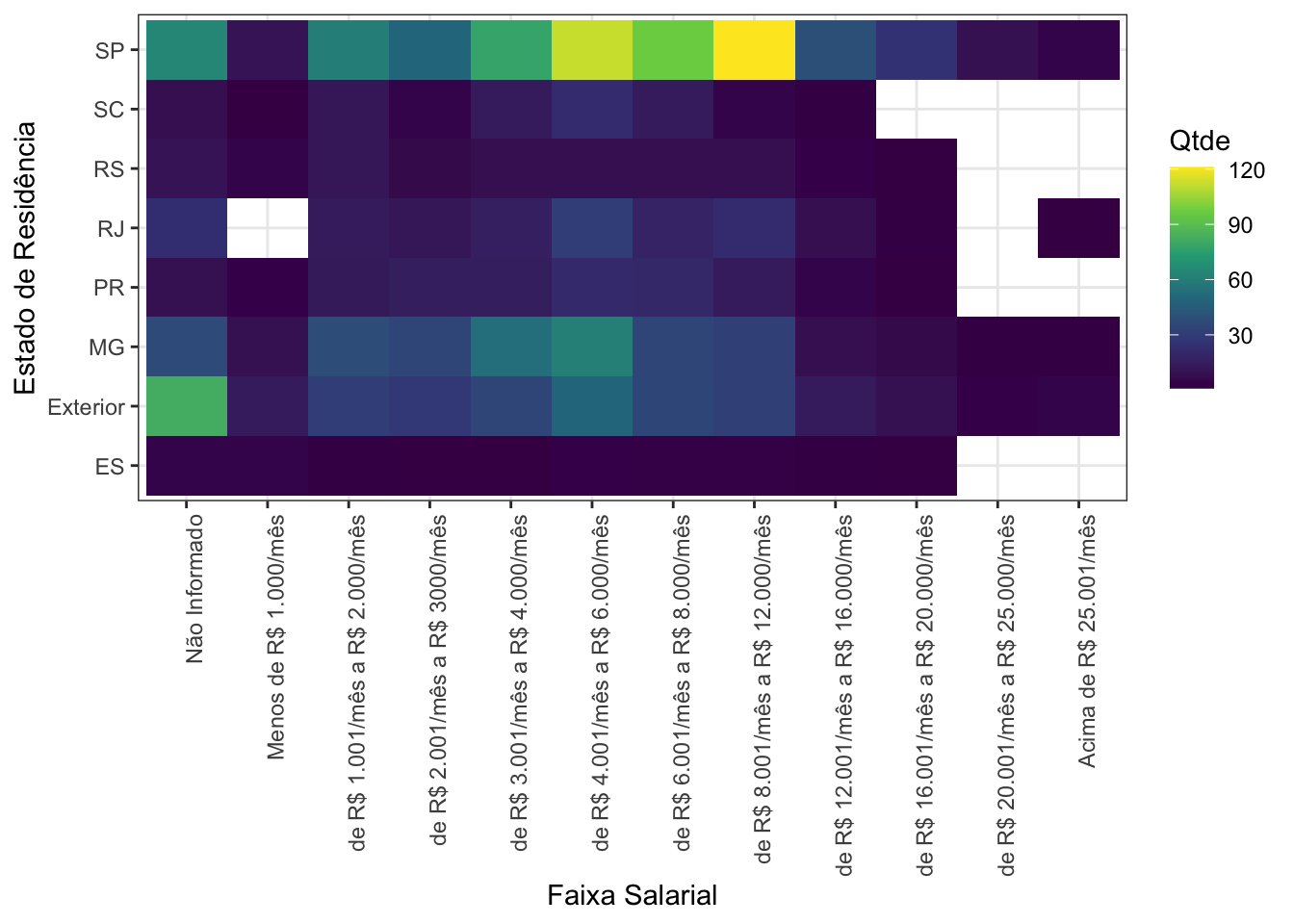
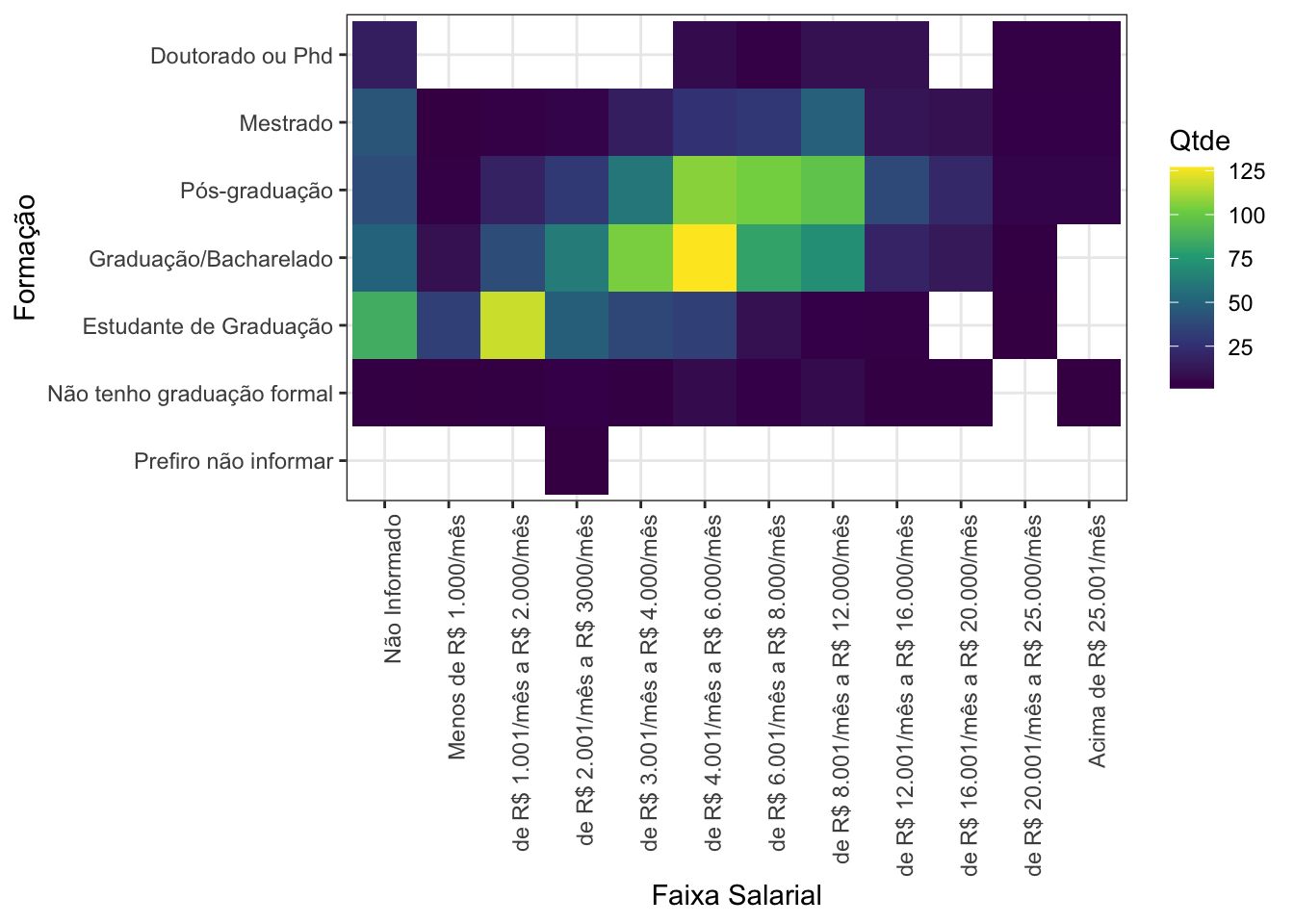
Por fim, as combinações de faixas salariais e formação mais comuns são de R$3.000 a R$12.000 por mês, para pessoas com graduação ou pós-graduação.
survey %>%
group_by(p8_degreee_level, p16_salary_range) %>%
count() %>%
ggplot(aes(x = p16_salary_range, y = p8_degreee_level, fill = n)) +
geom_tile() +
labs(x = "Faixa Salarial", y = "Formação", fill = "Qtde") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
scale_fill_viridis_c()
No próximo artigo veremos como ajustar um modelo preditivo capaz de prever o salário de um cientista de dados de acordo com algumas variáveis pré-estabelecidas.